
NVIDIA AI 发布 Canary-Qwen-2.5B:一款先进的 ASR-LLM 混合模型,在 OpenASR 排行榜上拥有 SoTA 性能
内容提要
NVIDIA发布了Canary-Qwen-2.5B模型,词错率为5.63%,在Hugging Face OpenASR中排名第一。该模型结合了自动语音识别和语言模型,支持音频摘要和问答,适用于多个行业,具有商业和开源特性。
关键要点
-
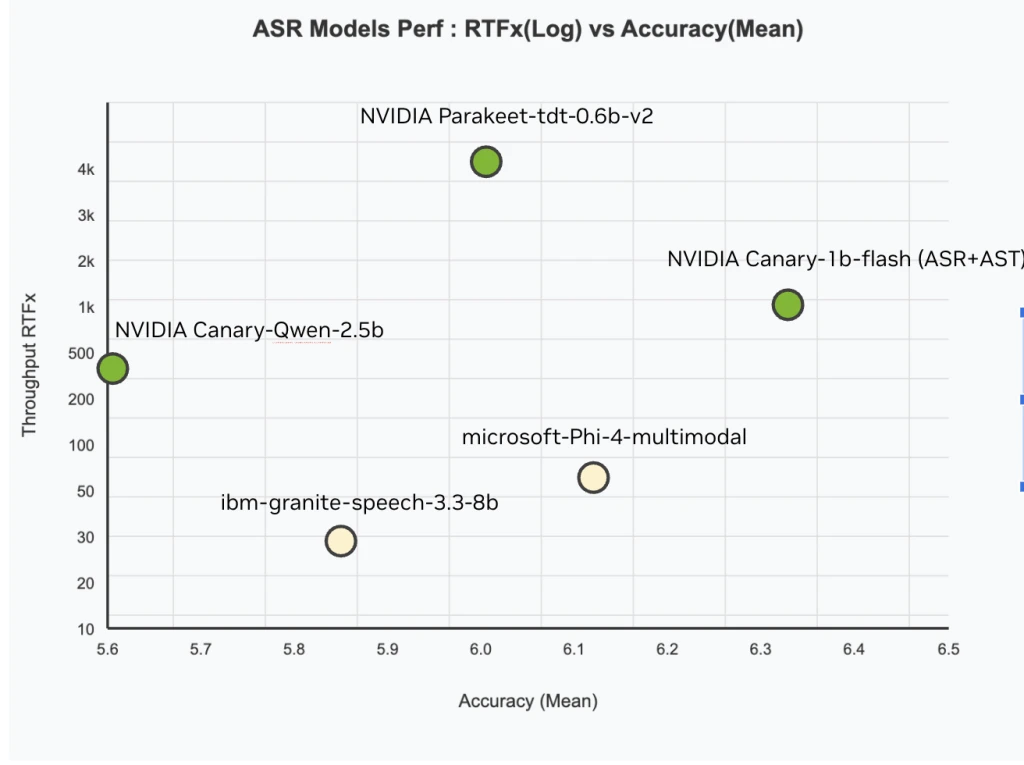
NVIDIA发布了Canary-Qwen-2.5B模型,词错率为5.63%,在Hugging Face OpenASR中排名第一。
-
该模型结合了自动语音识别和语言模型,支持音频摘要和问答,适用于多个行业。
-
Canary-Qwen-2.5B具有商业许可证(CC-BY)和开源特性,推动企业级语音AI的发展。
-
模型采用混合架构,统一了转录和后处理功能,提升了多模态灵活性。
-
该模型的实时因子(RTFx)为418,能够比实时速度快418倍处理输入音频。
-
训练数据集包含234,000小时的多样化英语语音,支持在嘈杂环境中的卓越泛化。
-
Canary-Qwen-2.5B针对多种NVIDIA GPU进行了优化,适用于云推理和内部边缘工作负载。
-
模型可用于企业转录服务、基于音频的知识提取、实时会议总结等多种应用。
-
开源模型促进社区驱动的语音AI进步,开发者可以创建特定任务的混合模型。
-
Canary-Qwen-2.5B不仅是ASR模型,更是将语音理解与通用语言模型相集成的蓝图。
延伸解读
技术创新与应用前景
Canary-Qwen-2.5B模型通过将自动语音识别与语言模型结合,展现了技术上的重大创新。这种混合架构不仅提升了转录精度,还支持音频摘要和问答等多种应用,适用于企业转录服务和实时会议总结等场景,具有广泛的商业潜力。
开源特性与社区驱动
该模型的开源特性使得开发者能够根据特定需求进行定制和扩展,促进了社区的参与和创新。通过与其他兼容的编码器和语言模型结合,开发者可以创建针对新领域或语言的特定任务模型,推动语音AI的进一步发展。
性能与部署优势
Canary-Qwen-2.5B的实时因子达到418,意味着其在处理输入音频时速度极快,适合大规模转录和实时字幕系统。这一性能优势使其在需要低延迟的应用场景中具有显著的竞争力,尤其是在医疗和法律等高要求行业。
延伸问答
Canary-Qwen-2.5B模型的词错率是多少?
Canary-Qwen-2.5B模型的词错率为5.63%。
Canary-Qwen-2.5B模型适用于哪些行业?
该模型适用于多个行业,包括医疗保健、法律和金融等。
Canary-Qwen-2.5B模型的实时因子是多少?
该模型的实时因子为418,意味着它可以比实时速度快418倍处理输入音频。
Canary-Qwen-2.5B模型的训练数据集包含多少小时的语音数据?
该模型的训练数据集包含234,000小时的多样化英语语音。
Canary-Qwen-2.5B模型的许可证类型是什么?
该模型获得CC-BY许可证,具有商业和开源特性。
Canary-Qwen-2.5B模型如何促进语音AI的进步?
通过开源该模型及其训练方案,促进社区驱动的语音AI进步,开发者可以创建特定任务的混合模型。
