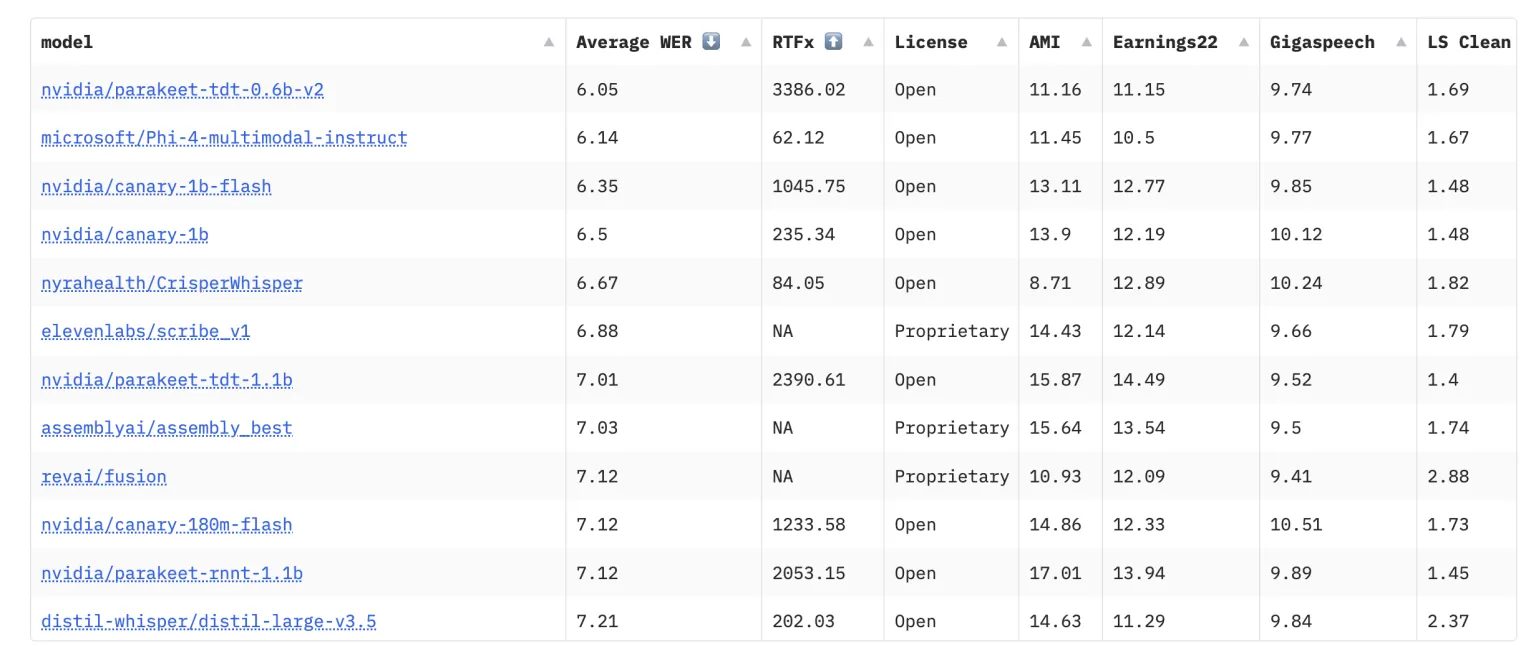
重新审视自动语音识别中的错误修正与专用模型
Apple Machine Learning Research
·

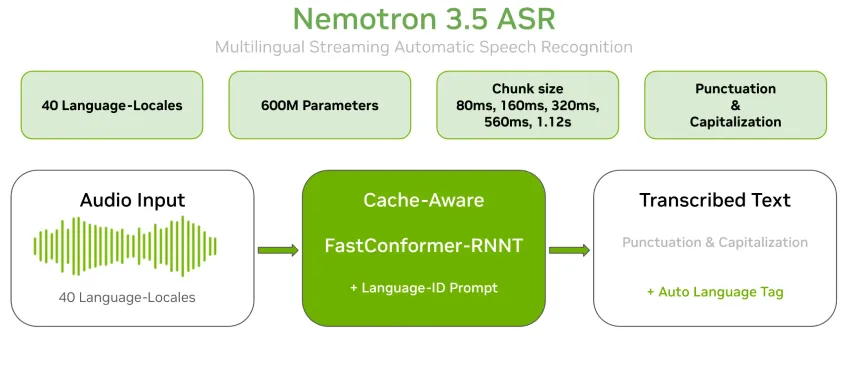

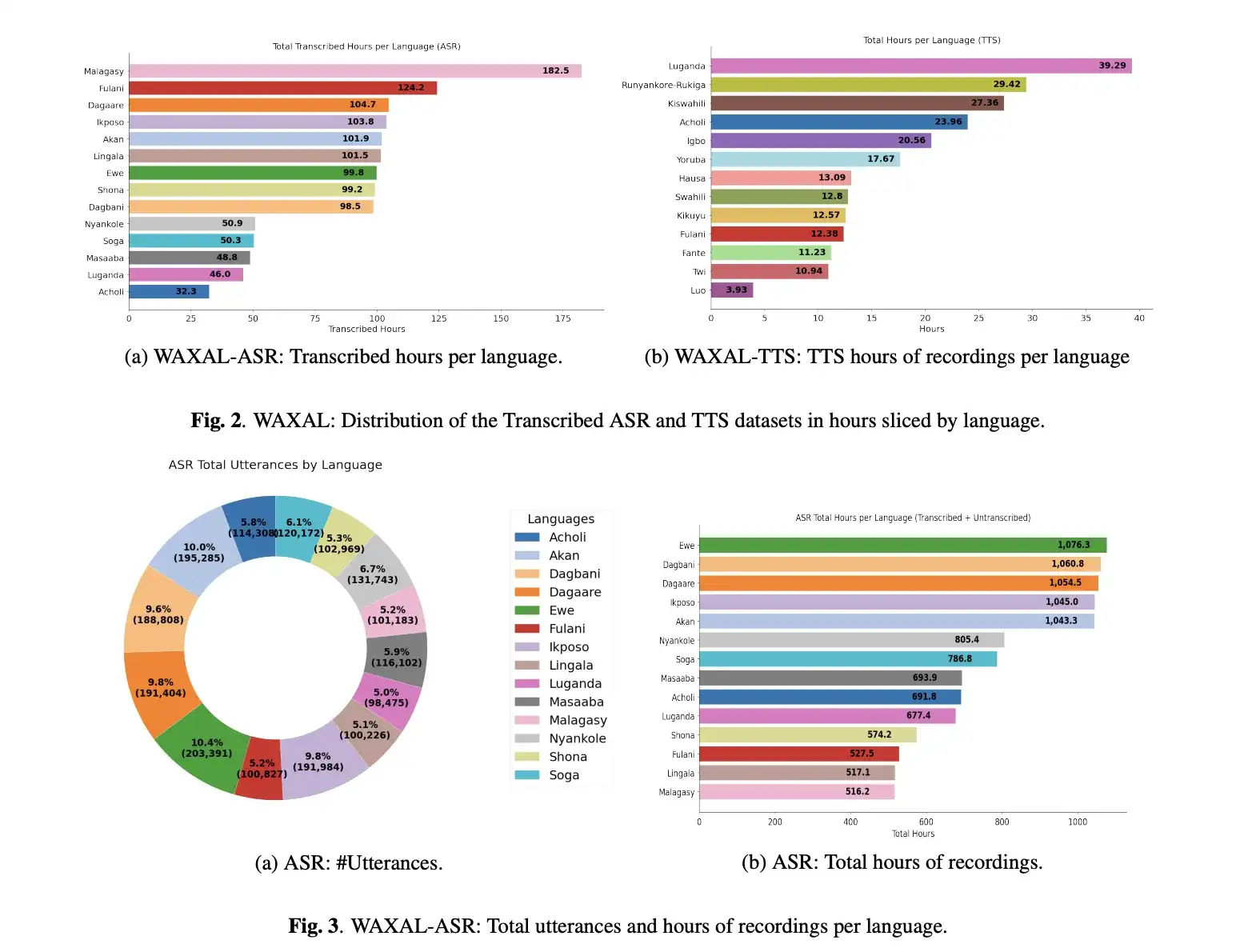

lyrichroma-一键将语音转换为视频的Python命令行工具
Yunfeng's Simple Blog
·


为语音识别启用差分隐私的联邦学习:基准测试、自适应优化器与梯度裁剪
Apple Machine Learning Research
·
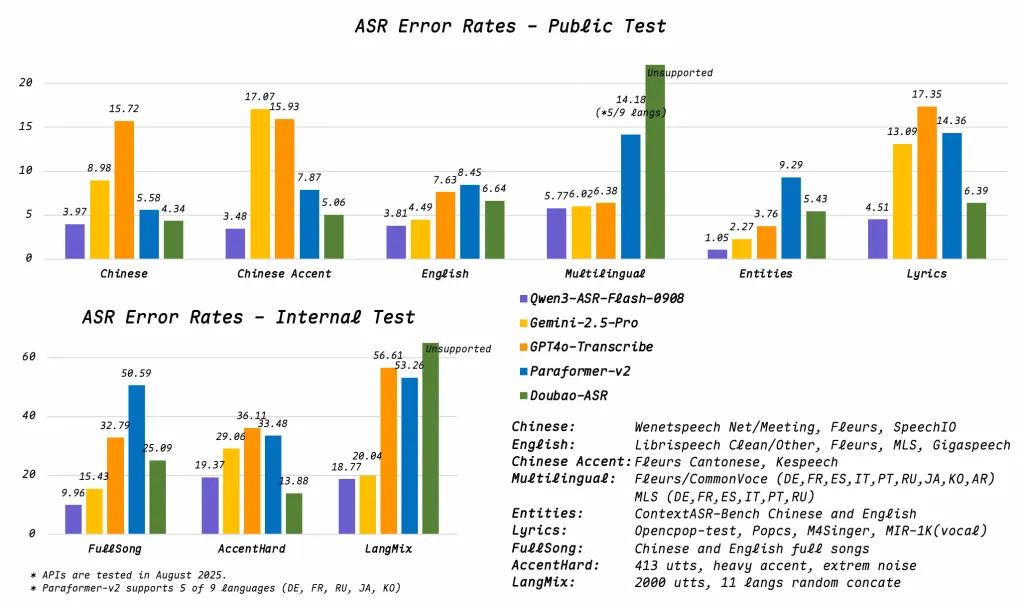
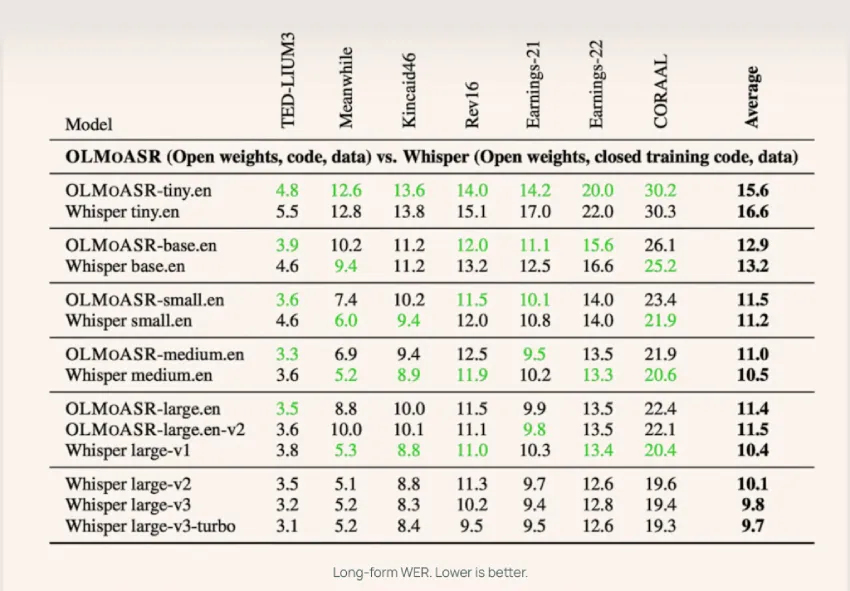
音调重音检测提升了预训练自动语音识别的性能
Apple Machine Learning Research
·
2025年国际语音通信会议语音可及性项目挑战
Apple Machine Learning Research
·
DiceHuBERT:基于自监督学习目标的HuBERT知识蒸馏
Apple Machine Learning Research
·
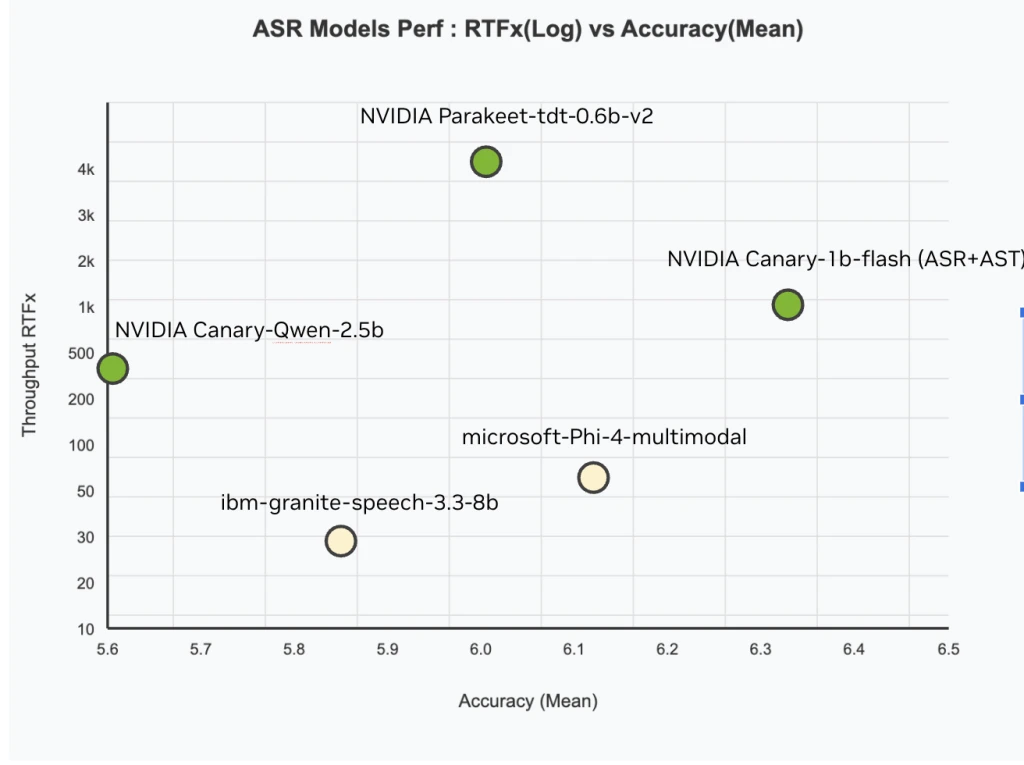
通过提示Whisper提高逐字转录和端到端错误检测的准确性
Apple Machine Learning Research
·