
NVIDIA 发布 Nemotron 3.5 ASR:一个拥有 6 亿参数、支持缓存的流式转录模型,可实时转录 40 种语言区域设置
内容提要
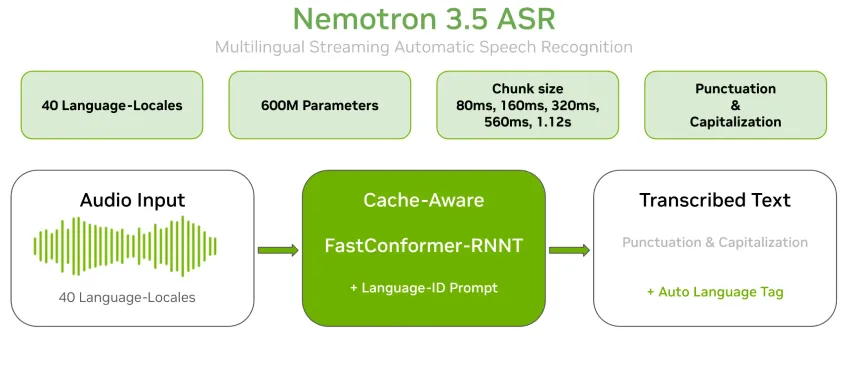
NVIDIA发布了Nemotron 3.5 ASR,这是一个支持40种语言的流式自动语音识别模型,拥有6亿参数。该模型采用FastConformer-RNNT架构,实时转录时无需单独处理标点和大小写,推理延迟可调,适合多种应用场景。经过微调,希腊语和保加利亚语的识别准确率显著提高。
关键要点
-
NVIDIA发布了Nemotron 3.5 ASR,这是一个拥有6亿参数的流式自动语音识别模型,支持40种语言。
-
该模型采用缓存感知型FastConformer-RNNT架构,实时转录时无需单独处理标点和大小写。
-
推理延迟可调,设置范围从80毫秒到1.12秒,适合低延迟和高吞吐量的应用场景。
-
经过微调,希腊语和保加利亚语的识别准确率显著提高,WER分别降低了32%和31%。
-
模型以开放权重形式发布,支持自托管,区别于封闭式API服务。
延伸解读
模型架构与性能优势
Nemotron 3.5 ASR采用缓存感知型FastConformer-RNNT架构,显著提高了处理效率。通过缓存机制,模型在处理音频时避免了重复计算,从而降低了延迟。这种设计使得模型在实时转录和高吞吐量批量转录中都能表现出色,适合多种应用场景。
语言支持与微调潜力
该模型支持40种语言,且通过开放权重形式发布,允许用户根据特定需求进行微调。NVIDIA的微调示例显示,希腊语和保加利亚语的识别准确率显著提高,WER分别降低了32%和31%。这为开发者提供了灵活性,可以针对特定领域或口音进行优化。
推理延迟的灵活性
Nemotron 3.5 ASR的推理延迟可调,范围从80毫秒到1.12秒,用户可以根据需求选择适合的延迟设置。较低的延迟适合实时应用,而较高的延迟则能提高识别精度。这种灵活性使得模型能够适应不同的使用场景,满足用户的多样化需求。
延伸问答
Nemotron 3.5 ASR的主要特点是什么?
Nemotron 3.5 ASR是一个拥有6亿参数的流式自动语音识别模型,支持40种语言,采用缓存感知型FastConformer-RNNT架构,实时转录时无需单独处理标点和大小写。
该模型如何处理标点和大小写?
Nemotron 3.5 ASR在实时转录时原生支持标点和大小写,无需单独处理。
推理延迟可以调节到什么范围?
推理延迟可调范围从80毫秒到1.12秒,适合不同的应用场景。
希腊语和保加利亚语的识别准确率如何?
经过微调后,希腊语的识别准确率提高,WER从35降至24,改善了32%;保加利亚语的WER从22降至15,改善了31%。
Nemotron 3.5 ASR与其他语音识别模型相比有什么优势?
Nemotron 3.5 ASR支持40种语言,开放权重,且在缓存处理上效率高,推理延迟可调,适合多种应用场景。
如何使用Nemotron 3.5 ASR进行自托管?
Nemotron 3.5 ASR以开放权重形式发布,用户可以在Hugging Face上获取并进行自托管。
