
Qwen3-ASR:阿里基于 Qwen3-Omni 构建的全新语音识别模型,实现更强大的语音识别性能
内容提要
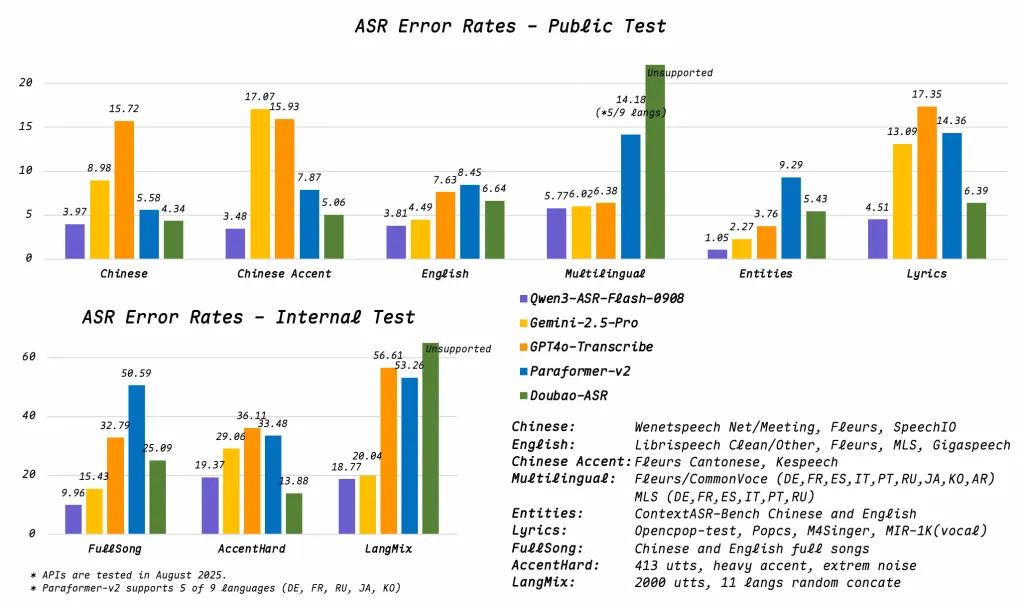
阿里云推出Qwen3-ASR Flash,一体化自动语音识别模型,支持11种语言的自动识别与转录,具备上下文注入和强大的音频处理能力,适用于教育、媒体和客户服务等领域,词错误率低于8%,易于部署。
关键要点
-
阿里云推出Qwen3-ASR Flash,一体化自动语音识别模型。
-
支持11种语言的自动检测和转录,包括英语、中文、阿拉伯语等。
-
具备上下文注入机制,用户可粘贴文本以提高识别准确性。
-
强大的音频处理能力,能够在嘈杂环境和低质量录音中保持性能。
-
词错误率保持在8%以下,适用于复杂场景。
-
单模型架构简化了多语言和音频上下文的管理。
-
适用领域包括教育、媒体和客户服务等。
-
内置语言检测功能,减少手动选择语言的需求。
-
Qwen3-ASR Flash易于部署,提供多语言支持和抗噪识别。
延伸解读
多语言支持的优势
Qwen3-ASR Flash支持11种语言的自动识别,这使其在全球市场上具有广泛的适用性。对于需要多语言服务的企业,如教育和客户支持,使用此模型可以显著降低开发和维护多个语言模型的复杂性,提升工作效率。
上下文注入机制的实用性
上下文注入机制允许用户在转录过程中粘贴特定文本,以提高识别准确性。这在处理专业术语或特定领域内容时尤为重要,能够有效减少误识别的情况,提升用户体验。
抗噪声能力的关键性
Qwen3-ASR在嘈杂环境中的表现尤为突出,词错误率低于8%。这一特性使其在实际应用中,尤其是在开放式识别系统中,能够保持较高的识别准确性,适合于各种复杂场景。
延伸问答
Qwen3-ASR Flash支持哪些语言的语音识别?
Qwen3-ASR Flash支持11种语言,包括英语、中文、阿拉伯语、德语、西班牙语、法语、意大利语、日语、韩语、葡萄牙语和俄语。
Qwen3-ASR Flash的词错误率是多少?
Qwen3-ASR Flash的词错误率保持在8%以下。
如何提高Qwen3-ASR Flash的识别准确性?
用户可以通过上下文注入机制,将文本粘贴到偏差转录中,以提高识别准确性。
Qwen3-ASR Flash适用于哪些领域?
Qwen3-ASR Flash适用于教育、媒体和客户服务等领域。
Qwen3-ASR Flash在嘈杂环境中的表现如何?
Qwen3-ASR Flash在嘈杂环境和低质量录音中仍能保持出色的性能。
Qwen3-ASR Flash的部署难度如何?
Qwen3-ASR Flash易于部署,用户只需使用一个模型即可完成所有任务。
