
InfiniBand 与 RoCEv2:为大规模 AI 选择合适的网络
内容提要
GPU 是人工智能的核心,但在大规模训练中,网络通信速度限制了性能。RDMA 和 GPUDirect 技术通过绕过 CPU 实现 GPU 直接通信,降低延迟。InfiniBand 性能高但成本高,RoCEv2 更经济灵活,适合现有以太网环境。选择应基于预算和性能需求。
关键要点
-
GPU 是人工智能的基础计算引擎,但网络通信速度限制了大规模训练的性能。
-
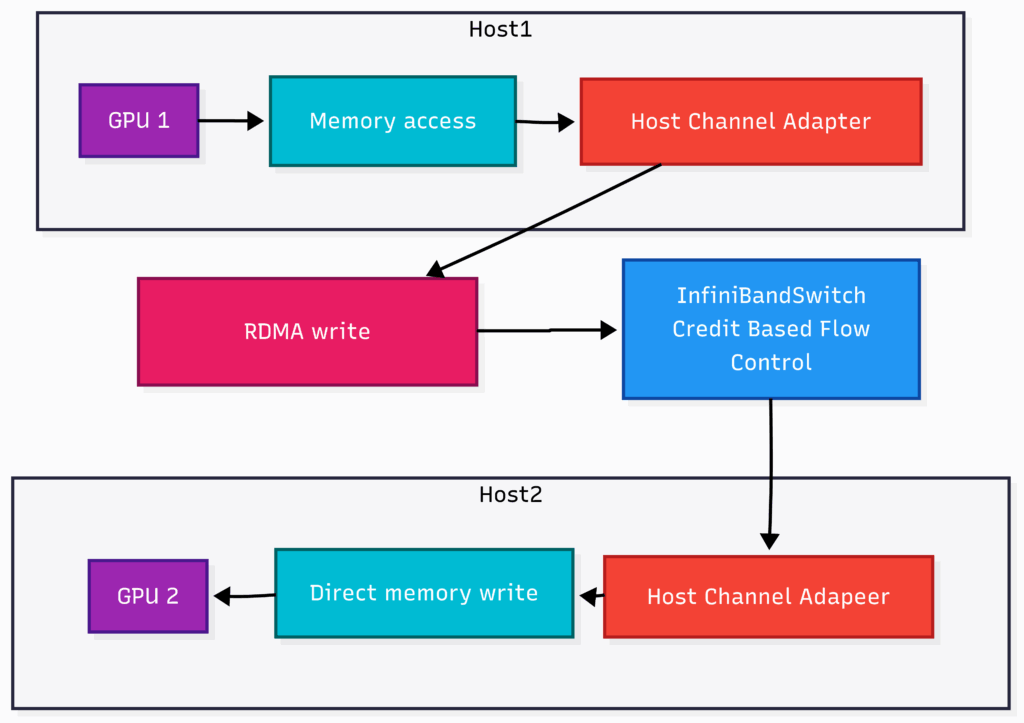
RDMA 和 GPUDirect 技术通过绕过 CPU 实现 GPU 直接通信,降低延迟。
-
InfiniBand 性能高但成本高,适合对速度要求极高的环境。
-
RoCEv2 更经济灵活,适合现有以太网环境,易于部署。
-
选择网络技术应基于预算和性能需求的平衡。
-
传统通信方式在 AI 工作负载中难以扩展,RDMA 提供了高吞吐量和低延迟的解决方案。
-
GPUDirect 允许 GPU 直接与其他硬件通信,跳过 CPU,提升效率。
-
InfiniBand 采用专为高速和低延迟设计的网络架构,支持 RDMA。
-
RoCEv2 利用现有以太网系统提供高速、低延迟的通信,但需要精心配置以避免数据包丢失。
-
在大规模 GPU 集群中,网络性能与 GPU 性能同样重要,RDMA 和 GPUDirect RDMA 技术可以减少延迟和中断。
延伸解读
网络选择的关键因素
在选择 InfiniBand 或 RoCEv2 时,用户需考虑预算、性能需求和现有基础设施的兼容性。InfiniBand 提供卓越的速度和低延迟,但成本较高,适合对性能要求极高的环境。而 RoCEv2 则更经济灵活,适合已有以太网环境,易于部署。
RDMA 技术的重要性
RDMA 技术在大规模 AI 训练中至关重要,它通过绕过 CPU 实现 GPU 之间的直接通信,显著降低延迟。随着 GPU 数量的增加,传统通信方式难以满足需求,RDMA 提供了高吞吐量和低延迟的解决方案,提升了整体训练效率。
RoCEv2 的配置挑战
尽管 RoCEv2 在成本和灵活性上具有优势,但其性能依赖于网络的精心配置。为了避免数据包丢失,必须正确设置优先级流量控制和拥塞控制机制。配置不当可能导致性能下降,因此在实施时需特别注意网络环境的优化。
延伸问答
InfiniBand 和 RoCEv2 的主要区别是什么?
InfiniBand 提供高性能和低延迟,但成本高,适合对速度要求极高的环境;而 RoCEv2 更经济灵活,适合现有以太网环境,但需要精心配置以避免数据包丢失。
什么是 RDMA 技术,它如何改善 GPU 之间的通信?
RDMA(远程直接内存访问)允许计算机直接访问远程内存,绕过 CPU,从而降低延迟并提高数据传输效率,特别适合 AI 训练环境。
GPUDirect 技术的优势是什么?
GPUDirect 允许 GPU 直接与其他硬件通信,跳过 CPU,从而减少数据传输延迟,提高整体效率。
选择 InfiniBand 还是 RoCEv2 时需要考虑哪些因素?
选择应基于预算、性能需求和愿意进行的配置调整之间的平衡。
RoCEv2 如何在以太网环境中实现 RDMA?
RoCEv2 通过在 UDP 和 IP 上运行,将 RDMA 引入标准以太网,利用现有的以太网硬件进行高速、低延迟的通信。
InfiniBand 的主要优缺点是什么?
InfiniBand 的优点是超低延迟和高带宽,适合大型 GPU 集群;缺点是硬件昂贵且管理难度较大。
