

SEA-LION v4:东南亚多模态语言模型
💡
原文中文,约2100字,阅读约需5分钟。
📝
内容提要
新加坡人工智能研究院发布的SEA-LION v4是一个开源的多模态语言模型,支持东南亚语言,具备文本和图像理解能力。该模型在多项语言任务中表现出色,尤其在资源匮乏的语言上,推动了数字公平。设计高效,适合多平台部署,适用于研究和行业应用。
🎯
关键要点
- 新加坡人工智能研究院发布了SEA-LION v4,这是一个开源的多模态语言模型。
- SEA-LION v4支持东南亚语言,具备文本和图像理解能力。
- 该模型在多项语言任务中表现出色,尤其在资源匮乏的语言上。
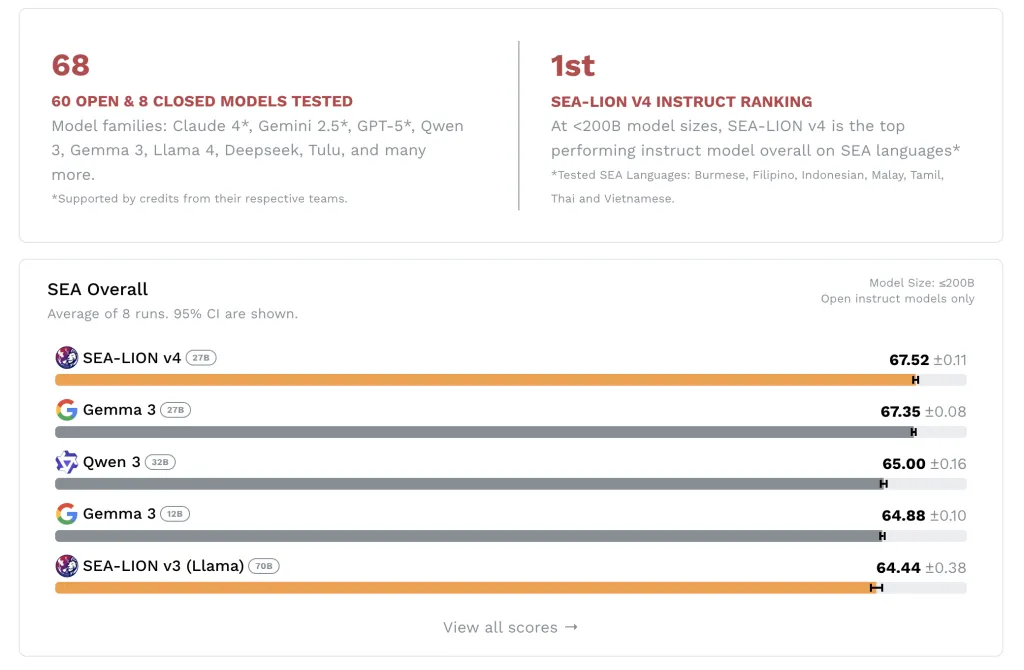
- SEA-LION v4在SEA-HELM基准测试中名列前茅,优于多个开源模型。
- 模型设计高效,适合在标准硬件平台上部署。
- SEA-LION v4采用商业许可,降低了初创企业和研究人员的采用门槛。
- 该模型支持多种平台的分发,包括Hugging Face和谷歌云等。
- SEA-LION v4是首个多模态版本,支持文本和图像的结合使用。
- 模型支持128K标记上下文窗口,适合长文档的推理。
- SEA-LION v4包含函数调用和结构化输出功能,适用于企业应用。
- 该模型基于超过1万亿个标记进行训练,特别关注东南亚数据集。
- SEA-LION v4在多语言任务中表现优异,是推动数字公平的关键工具。
- 模型在全球任务中仍保持竞争力,适合通用部署。
➡️
