
💡
原文中文,约2800字,阅读约需7分钟。
📝
内容提要
谷歌发布了Gemini 3.1 Flash Live预览版,旨在实现低延迟的实时语音交互。该模型通过原生音频处理提升了嘈杂环境中的语音识别准确性,并支持双向流式传输,允许用户中断对话。同时,开发者可调整推理深度,以优化速度与准确性。
🎯
关键要点
- 谷歌发布Gemini 3.1 Flash Live预览版,旨在实现低延迟的实时语音交互。
- 该模型通过原生音频处理提升了嘈杂环境中的语音识别准确性。
- 支持双向流式传输,允许用户中断对话。
- 开发者可调整推理深度,以优化速度与准确性。
- Gemini 3.1 Flash Live简化了传统的语音处理流程,显著降低了延迟。
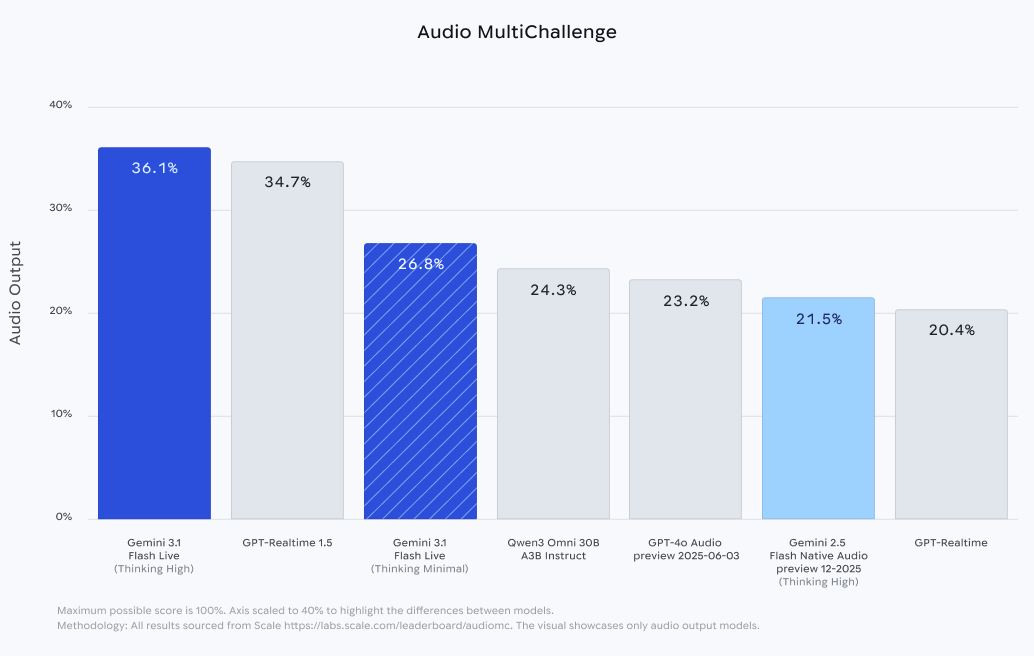
- 模型在ComplexFuncBench Audio测试中取得90.8%的高分,展示了其强大的智能推理能力。
- 使用WebSocket实现有状态的双向流,支持音频、视频帧和转录文本的同时传输。
- 开发者可以通过thinkingLevel参数调整模型的推理深度,平衡对话速度和思考深度。
- 目前模型处于开发者预览阶段,仅支持特定的音频格式和同步函数调用。
❓
延伸问答
Gemini 3.1 Flash Live的主要功能是什么?
Gemini 3.1 Flash Live旨在实现低延迟的实时语音交互,并通过原生音频处理提升语音识别准确性。
Gemini 3.1 Flash Live如何处理嘈杂环境中的语音?
该模型通过原生音频处理显著提升了在嘈杂环境中的语音识别准确性,能够从背景噪音中识别相关语音。
开发者如何调整Gemini 3.1 Flash Live的推理深度?
开发者可以通过thinkingLevel参数在“最低”、“低”、“中”和“高”之间进行选择,以优化对话速度和推理深度。
Gemini 3.1 Flash Live的双向流式传输有什么优势?
双向流式传输允许用户在AI说话过程中中断对话,模拟人类对话的节奏,提升交互的自然性。
Gemini 3.1 Flash Live在ComplexFuncBench Audio测试中的表现如何?
该模型在ComplexFuncBench Audio测试中取得了90.8%的高分,展示了其强大的智能推理能力。
目前Gemini 3.1 Flash Live的使用限制是什么?
该模型目前处于开发者预览阶段,仅支持特定的音频格式和同步函数调用。
➡️
