
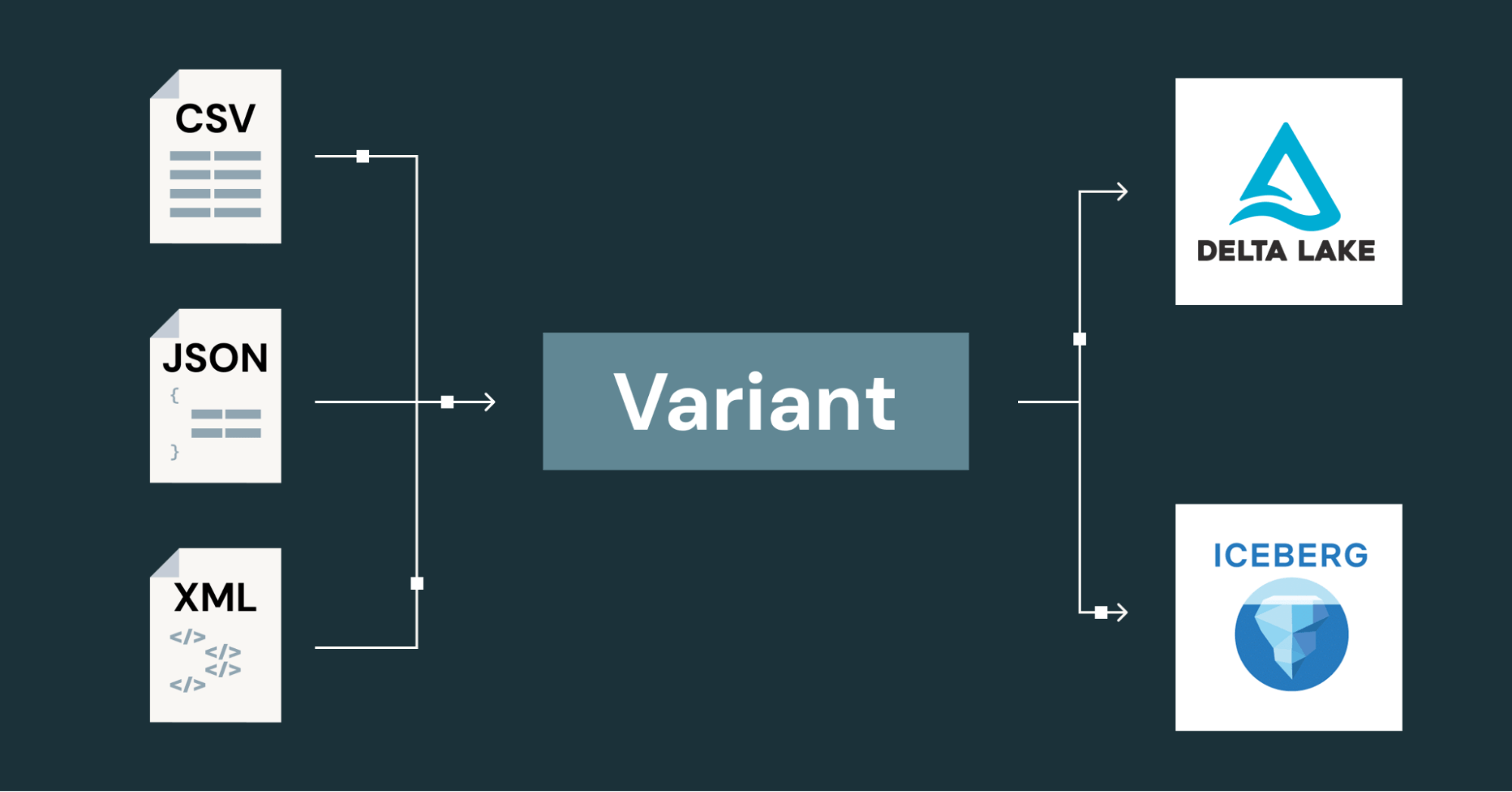
介绍Variant:Apache Parquet™、Delta Lake和Apache Iceberg™中半结构化数据的新开放标准
内容提要
半结构化数据在AI和应用日志中普遍存在,但模式变化导致存储和查询困难。Apache Parquet™的Variant数据类型以紧凑的二进制格式存储数据,提升查询性能,并被Delta Lake和Apache Iceberg™采纳。通过二进制编码和分片技术,Variant提高数据处理效率,减少I/O和存储需求。
关键要点
-
半结构化数据在AI、应用日志和遥测中普遍存在,但模式变化使存储和查询变得困难。
-
Apache Parquet™的Variant数据类型以紧凑的二进制格式存储数据,提升查询性能。
-
Variant数据类型是半结构化数据的开放标准,支持Apache Spark™、Delta Lake和Apache Iceberg™。
-
Variant提供灵活性和性能,优于将半结构化数据存储为字符串或结构体。
-
Variant的推出引起了Apache Iceberg™和Apache Arrow™等其他开源项目的关注。
-
Variant在Parquet社区获得批准,为整个湖仓生态系统提供了标准的开放数据类型。
-
Variant使用二进制编码格式提供灵活的数据存储接口,提升性能。
-
Variant的剥离技术可以更高效地存储数据,减少I/O和存储需求。
-
剥离技术使得查询时只需获取所需字段,减少了I/O操作。
-
剥离后的字段可以利用Parquet的优化,实现高效的行组和列页面跳过。
-
剥离字段的列式存储方式可以更有效地压缩数据,减少存储大小。
延伸解读
半结构化数据的挑战与机遇
半结构化数据在现代应用中越来越普遍,但其模式变化给存储和查询带来了挑战。传统上,使用字符串存储虽然灵活,但性能较差。Variant数据类型的引入为解决这一问题提供了新的思路,能够在保持灵活性的同时显著提升查询性能。
Variant的技术优势
Variant采用紧凑的二进制编码格式,利用偏移量导航数据结构,避免了对整个数据的读取,从而提高了处理效率。此外,剥离技术使得查询时只需获取必要字段,进一步减少了I/O操作和存储需求。这些技术优势使得Variant在处理半结构化数据时表现出色。
生态系统的统一与发展
Variant的推出不仅为Apache Parquet™社区带来了新的开放标准,还引起了Apache Iceberg™和Apache Arrow™等项目的关注。通过将Variant整合到多个开源项目中,促进了湖仓生态系统的统一,用户可以在不同平台上享受到一致的性能和灵活性。
延伸问答
什么是Variant数据类型,它的主要优势是什么?
Variant数据类型是一种在Apache Parquet™中批准的半结构化数据存储格式,主要优势是以紧凑的二进制格式存储数据,提升查询性能和灵活性。
Variant如何提高半结构化数据的查询性能?
Variant通过使用二进制编码和偏移量导航,避免了读取整个数据值,从而显著提高了查询性能。
剥离技术在Variant中是如何工作的?
剥离技术将Variant值中的常见字段提取并单独存储,这样查询时只需获取所需字段,减少了I/O操作,提高了性能。
Variant数据类型如何与其他开源项目兼容?
Variant被设计为开放标准,已被Apache Spark™、Delta Lake和Apache Iceberg™等多个开源项目支持,促进了生态系统的统一。
使用Variant数据类型有什么实际应用场景?
Variant数据类型适用于AI、应用日志和遥测等领域,能够有效处理半结构化数据,提升存储和查询效率。
为什么传统的字符串存储方式在处理半结构化数据时表现不佳?
传统的字符串存储方式需要解析整个字符串,导致查询性能差,而Variant通过二进制格式存储提高了效率。
