
BM42:混合搜索的新基准
原文英文,约2600词,阅读约需10分钟。
📝
内容提要
BM42是对BM25的改进,结合了IDF和变换器的注意力机制,适用于现代检索系统。BM25在文本检索中有效,但在短文档和RAG系统中表现不佳。BM42通过利用变换器的语义信息,提升了检索速度和准确性,适合多语言支持。
🎯
关键要点
-
BM42是对BM25的改进,结合了IDF和变换器的注意力机制。
-
BM25在文本检索中有效,但在短文档和RAG系统中表现不佳。
-
BM42通过利用变换器的语义信息,提升了检索速度和准确性。
-
BM42适合多语言支持,能够处理不同语言的文本。
-
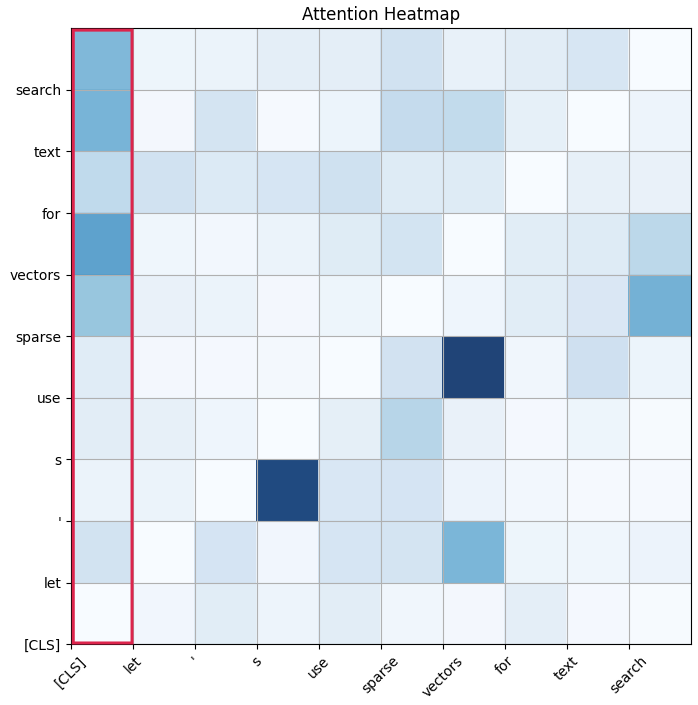
BM42的评分公式结合了IDF和变换器的注意力矩阵。
-
BM42在短文本检索中表现优于BM25,尤其是在问答任务中。
-
BM42的实现不需要额外的训练,可以使用任何变换器模型。
-
BM42通过反向词元化解决了传统变换器在检索任务中的词元化问题。
❓
延伸问答
BM42与BM25相比有什么改进?
BM42结合了IDF和变换器的注意力机制,提升了检索速度和准确性,尤其在短文本和问答任务中表现更佳。
BM42如何处理多语言文本?
BM42适合多语言支持,可以处理不同语言的文本,只要有相应的变换器模型。
BM42的评分公式是怎样的?
BM42的评分公式为:score(D,Q) = ∑ IDF(q_i) × Attention(CLS, q_i),结合了IDF和变换器的注意力矩阵。
BM42在短文本检索中表现如何?
BM42在短文本检索中表现优于BM25,特别是在问答任务中,能够更准确地匹配相关信息。
BM42的实现需要额外训练吗?
BM42的实现不需要额外的训练,可以使用任何变换器模型。
BM42如何解决传统变换器的词元化问题?
BM42通过反向词元化技术解决了传统变换器在检索任务中的词元化问题,能够合并子词的注意力权重。
🏷️
