
声学模型和语言模型融合的N种方式
内容提要
本文探讨了语音识别中声学模型与语言模型的融合方法,包括浅层融合、语言模型重评分、密度比和内部语言模型估计等。这些融合策略能够提高识别精度并降低计算开销。
关键要点
-
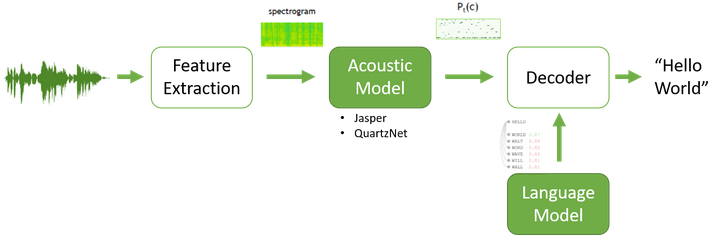
语音识别算法的目标是从声学特征中找到最可能的词序列。
-
语言模型负责计算词序列的概率估计,并引导备选词假设的搜索结果。
-
语言模型分为基于统计的模型和基于神经网络的模型。
-
浅层融合是将声学模型和语言模型的得分加权求和的传统方法。
-
语言模型重评分在句子解码后对n-best结果进行打分,计算量较小但精度下降。
-
密度比方法通过贝叶斯定理解决跨域问题,改进了声学模型的识别结果。
-
内部语言模型估计假设声学模型和语言模型具有独立参数,使用联合软最大近似方法进行估计。
-
加权有限状态转换器(WFST)用于处理带权重的符号转换问题,结合声学模型、词典和语言模型进行解码。
延伸解读
声学模型与语言模型的关系
声学模型和语言模型在语音识别中扮演着不同但互补的角色。声学模型负责从音频信号中提取特征,而语言模型则通过计算词序列的概率来引导识别过程。理解这两者的关系有助于优化语音识别系统的设计,选择合适的融合策略以提高识别精度。
融合方法的优缺点
不同的融合方法各有优缺点。浅层融合简单易用,但计算量较大;语言模型重评分虽然减少了计算开销,但可能导致精度下降。密度比方法在跨域问题上表现更佳,但需要额外的训练。选择合适的方法需根据具体应用场景和资源限制进行权衡。
内部语言模型的应用
内部语言模型的引入为解决跨域问题提供了新的思路。通过在声学模型的源域再训练语言模型,可以有效改善识别结果。这种方法在解码时介入,不影响声学模型的训练过程,适合需要高效处理多领域数据的应用场景。
延伸问答
声学模型和语言模型的融合方法有哪些?
主要有浅层融合、语言模型重评分、密度比和内部语言模型估计等方法。
什么是浅层融合?
浅层融合是将声学模型和语言模型的得分加权求和的传统方法。
语言模型重评分的优缺点是什么?
优点是计算量较小,缺点是精度相对于浅层融合有所下降。
密度比方法如何改善声学模型的识别结果?
密度比方法通过贝叶斯定理解决跨域问题,从而改进声学模型的识别结果。
内部语言模型估计的基本原理是什么?
内部语言模型估计假设声学模型和语言模型具有独立参数,并使用联合软最大近似方法进行估计。
加权有限状态转换器(WFST)在语音识别中有什么作用?
WFST用于处理带权重的符号转换问题,结合声学模型、词典和语言模型进行解码。
