
NVIDIA AI 发布 Streaming Sortformer:实时说话人日志分析工具,可立即识别会议和通话中谁在说话
内容提要
NVIDIA 发布了 Streaming Sortformer,能够在嘈杂环境中实时识别最多四位说话者,支持英语和普通话,具备低延迟和高精度,适用于会议记录和联络中心,推动对话式 AI 发展。
关键要点
-
NVIDIA 发布了 Streaming Sortformer,能够在嘈杂环境中实时识别最多四位说话者。
-
该模型支持英语和普通话,具备低延迟和高精度,适用于会议记录和联络中心。
-
Streaming Sortformer 实现了实时、多说话人跟踪,能够为每句话标记说话者标签和时间戳。
-
该模型经过 GPU 加速优化,能够与 NVIDIA NeMo 和 Riva 平台无缝集成。
-
Streaming Sortformer 在普通话和非英语数据集上表现出色,具有广泛的语言兼容性。
-
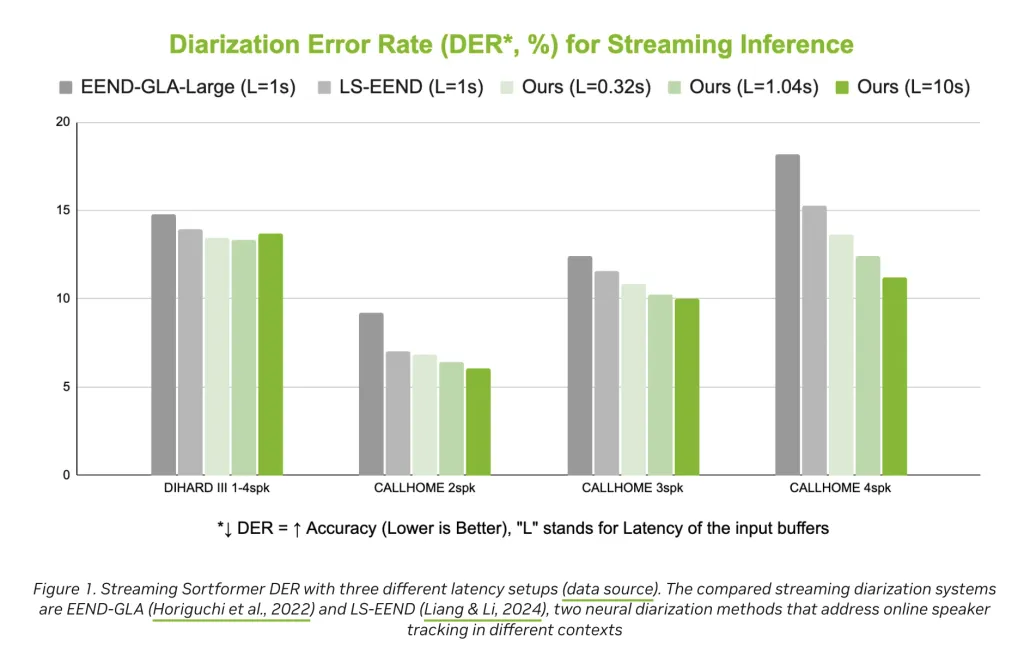
该模型在实际基准测试中优于其他最新替代方案,提供竞争力的二值化错误率 (DER)。
-
Streaming Sortformer 的核心架构结合了卷积神经网络 (CNN)、Conformers 和 Transformers 的优势。
-
模型通过动态内存缓存确保每个参与者在对话中保持一致的标签。
-
Streaming Sortformer 是开放的、生产级的,能够集成到现有工作流程中。
-
该模型在会议、联络中心、语音机器人和企业合规性等领域具有广泛的应用潜力。
-
尽管在基准测试中表现优异,但模型目前优化于最多四位发言者的场景,未来研究需扩展到更大群体。
-
Streaming Sortformer 是一个可立即投入生产的工具,预计将在未来成为实时说话人分类的标准。
延伸解读
实时应用场景
Streaming Sortformer 的实时说话人识别功能在多个领域具有广泛应用潜力。尤其是在会议记录和联络中心中,能够即时生成带有发言者标签的记录,帮助团队更好地跟踪讨论内容和分配任务。这种技术的引入将显著提高工作效率和沟通质量。
技术架构优势
该模型结合了卷积神经网络、Conformers 和 Transformers 的优势,形成了一种混合架构。这种设计不仅提升了处理速度,还增强了在嘈杂环境中的识别能力,使其在实际应用中表现出色。开发者可以利用这一架构,快速集成到现有工作流程中。
局限性与未来展望
尽管 Streaming Sortformer 在多说话人识别中表现优异,但目前仅优化于最多四位发言者的场景。未来的研究需要扩展其能力,以支持更多参与者的对话。此外,在不同声学环境下的表现也需进一步验证,以确保其广泛适用性。
延伸问答
Streaming Sortformer 的主要功能是什么?
Streaming Sortformer 能够在嘈杂环境中实时识别最多四位说话者,并为每句话标记说话者标签和时间戳。
Streaming Sortformer 支持哪些语言?
该模型支持英语和普通话,并在非英语数据集上也表现出色。
Streaming Sortformer 如何确保实时处理的低延迟?
模型通过处理小块重叠的音频数据,并动态标记说话者,确保低延迟和高精度。
Streaming Sortformer 在实际应用中有哪些潜力?
它可用于会议记录、联络中心合规日志、语音机器人和企业合规性等多个领域。
Streaming Sortformer 的架构特点是什么?
其核心架构结合了卷积神经网络 (CNN)、Conformers 和 Transformers 的优势,支持端到端训练。
Streaming Sortformer 的局限性是什么?
该模型目前优化于最多四位发言者的场景,未来需要扩展到更大群体。
