Hydaway Digital Corp.在其RealityChek平台推出流媒体音频检测功能,能够实时识别合成或篡改的音频,适用于实时电话和呼叫中心等场景,帮助企业在欺诈发生前进行检测,提升安全性。该系统通过分析频谱模式和韵律标记等特征,实时评估音频的真实性,符合Hydaway推动实时信任决策的战略目标。
这篇文章介绍了一款基于百度实时语音识别API的网页浏览器语音输入法,支持简体中文和英语,能够实时将语音转为文字,主要用于个人使用。GitHub地址提供了更多信息。
dots.ocr 是小红书 hi lab 发布的多语言文档解析模型,具备轻量化设计和精准文本提取能力,支持100种语言,能处理模糊扫描件和倾斜快拍,识别效果优于大型模型,适合实时文字识别。
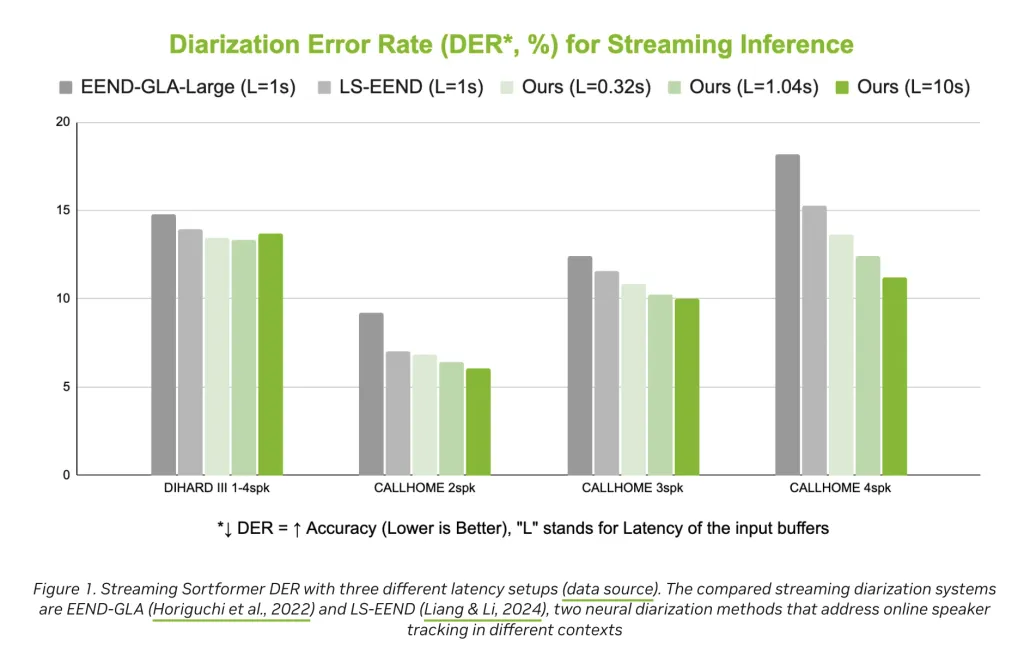
NVIDIA 发布了 Streaming Sortformer,能够在嘈杂环境中实时识别最多四位说话者,支持英语和普通话,具备低延迟和高精度,适用于会议记录和联络中心,推动对话式 AI 发展。
本文介绍了一款基于PaddleOCR的WinForm程序,演示如何实时捕捉视频并进行文字识别。该项目使用.NET 8.0开发,集成了PaddleOCRSharp和OpenCvSharp4,支持自动和手动OCR识别,具备多语言识别能力,代码结构简洁,适合开发者学习和扩展。
本研究提出了一种新颖的轻量级多模态人工智能框架,旨在提高海洋多场景识别的精度。该框架结合图像数据、文本描述和分类向量,实验准确率达到98%,比之前最佳模型提升3.5%。此技术适用于资源受限平台,提供高性能的实时识别解决方案。
微软的语音识别服务通过Speech Studio提供高效的说话人区分解决方案,适用于电话录音等场景。使用C# SDK可实现实时语音识别,输出文本和说话人ID,便于后续处理。
本研究提出了一种基于短程FMCW雷达的实时面部表情识别方法,系统使用一发射天线和三接收天线,在60 GHz频段实现了98.91%的分类准确率,展示了低成本FMCW雷达在面部表情识别中的应用潜力。
本研究提出了一种基于双向长短期记忆(BiLSTM)神经网络的实时运动分类方法,旨在提高运动识别在真实环境中的鲁棒性和通用性。该模型结合关节角度和坐标数据,测试准确率超过99%。
本研究提出了一种基于多站地震波形和语义分割模型的实时火山地震事件识别框架。通过将多通道信号转为二维图像,实现了同步检测和分类。UNet模型在火山数据估计中表现优异,F1和IoU得分分别达到0.91和0.88,显示出其在噪声和未知数据集中的优势。
本研究提出SPRMamba框架,以提高内镜下黏膜下解剖手术(ESD)中手术阶段的实时识别准确性。该框架利用Mamba进行长期时间建模,并引入Scaled Residual TranMamba模块以捕获细微特征。实验结果表明,其识别效果优于现有最佳方法,且具有更强的鲁棒性。
本研究探讨了电话诈骗对个人和社区的威胁,并提出了一种基于大语言模型的实时检测方法,以识别潜在的诈骗电话并提供即时保护。尽管前景良好,但仍面临数据偏见和召回率低等挑战,需要进一步研究。
本文探讨了在资源受限设备上实现基于Conformer的语音识别系统的挑战与解决方案。研究提出了一系列模型架构调整和优化方法,使得在小型可穿戴设备上实现高效、低能耗的实时语音识别,且不降低准确性。该系统的识别速度超过实时5.26倍,具有广泛的应用潜力。
完成下面两步后,将自动完成登录并继续当前操作。