
使用LlamaIndex和Ray构建与扩展强大的查询引擎
原文英文,约2500词,阅读约需9分钟。
📝
内容提要
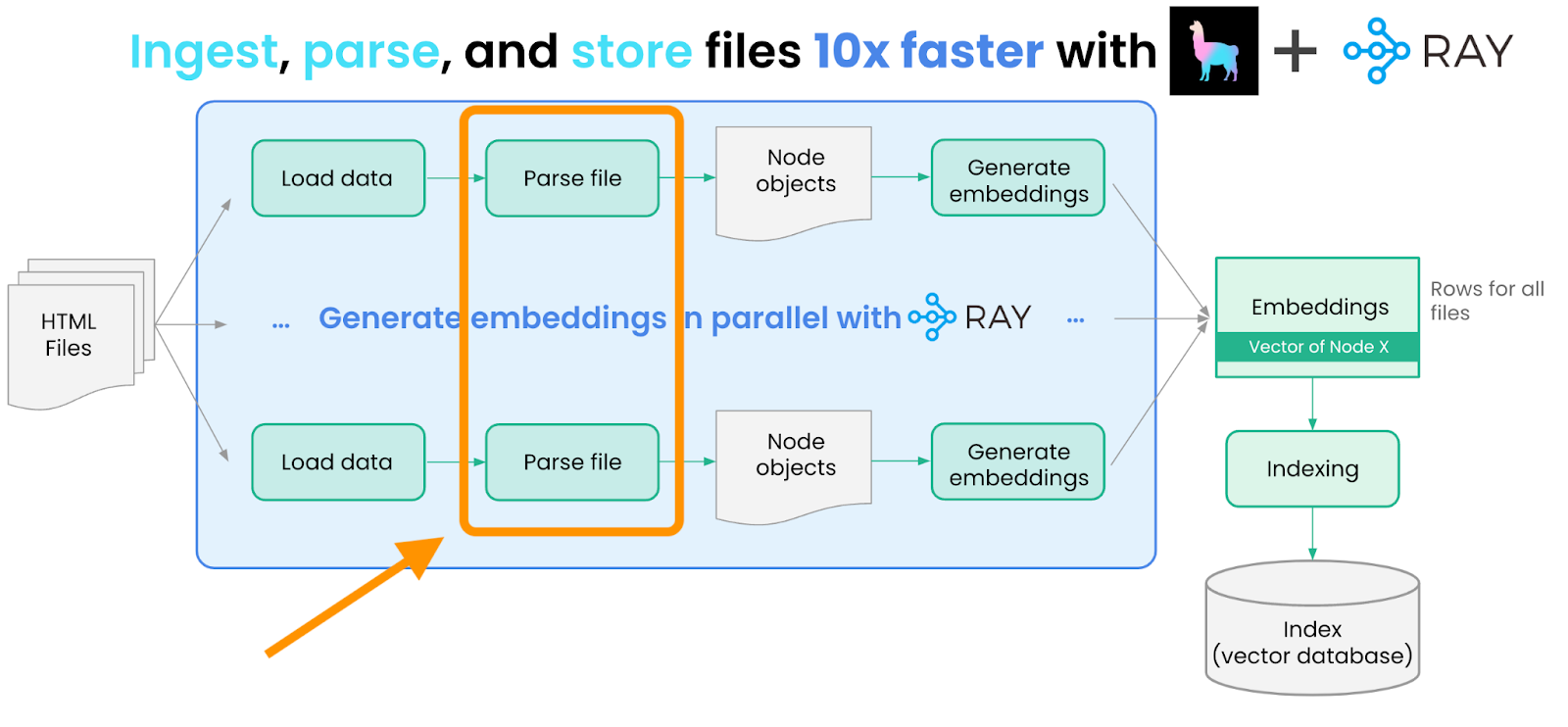
本文介绍了如何使用LlamaIndex和Ray构建查询引擎,以从Ray的文档和博客中提取信息。LlamaIndex负责数据的加载、解析和索引,而Ray提供高效的并行处理能力。通过构建数据管道和查询引擎,用户能够快速获取Ray的见解并部署到生产环境中,实现对多个数据源的语义搜索。
🎯
关键要点
-
LlamaIndex和Ray结合使用,可以构建查询引擎,从Ray的文档和博客中提取信息。
-
LlamaIndex负责数据的加载、解析和索引,解决了多数据源索引和复杂查询的问题。
-
Ray提供高效的并行处理能力,解决了大规模文档的索引和部署问题。
-
通过并行处理,用户可以快速加载、解析和嵌入Ray文档和博客内容。
-
LlamaIndex的查询引擎可以处理自然语言查询,并返回相关的文档和信息。
-
使用Ray Serve可以轻松将查询引擎部署到生产环境中,支持用户请求。
-
示例查询展示了如何通过查询引擎获取Ray文档和博客的综合信息。
❓
延伸问答
LlamaIndex和Ray如何结合使用来构建查询引擎?
LlamaIndex负责数据的加载、解析和索引,而Ray提供高效的并行处理能力,二者结合可以快速构建查询引擎。
使用LlamaIndex构建查询引擎的主要步骤是什么?
主要步骤包括数据加载、解析、嵌入和索引,最后通过查询引擎进行自然语言查询。
Ray在处理大规模文档时有哪些优势?
Ray提供高效的并行处理能力,能够加速数据的加载和索引,适合处理成千上万的文档。
如何将LlamaIndex的查询引擎部署到生产环境中?
可以使用Ray Serve轻松部署查询引擎,通过定义类和添加装饰器来创建查询端点。
LlamaIndex的查询引擎如何处理自然语言查询?
查询引擎接收自然语言输入,并通过索引返回相关文档和信息,支持语义搜索。
LlamaIndex和Ray的结合适合哪些应用场景?
适合需要从多个数据源提取信息并进行语义搜索的应用场景,如文档检索和知识管理。
🏷️
