
在vLLM上运行高效且准确的AI代理,使用NVIDIA Nemotron 3 Nano
内容提要
NVIDIA推出Nemotron 3 Nano,采用混合Mamba-Transformer MoE架构,支持1M上下文长度,适合高效AI应用。该模型开源,具备出色的编码和推理能力,适用于多行业AI代理开发。
关键要点
-
NVIDIA推出Nemotron 3 Nano,采用混合Mamba-Transformer MoE架构。
-
Nemotron 3 Nano支持1M上下文长度,适合高效AI应用。
-
该模型开源,具备出色的编码和推理能力。
-
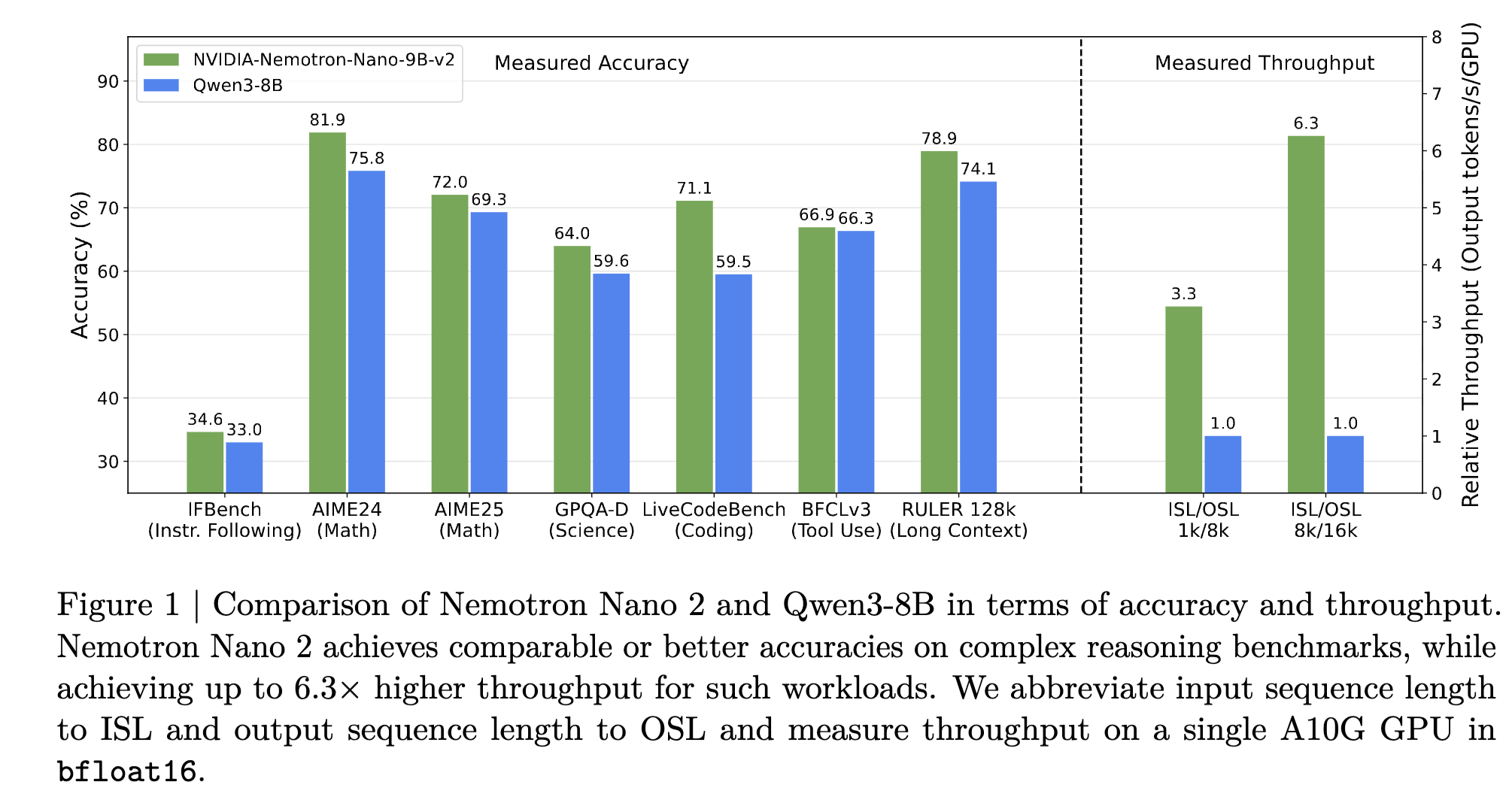
Nemotron 3 Nano在多个基准测试中表现优异,如SWE Bench Verified和GPQA Diamond。
-
模型架构为混合专家(MoE),支持最优准确性与最小推理令牌生成。
-
模型大小为30B,具有3B活跃参数。
-
支持NVIDIA RTX Pro 6000、DGX Spark、H100和B200等GPU。
-
通过vLLM实现加速推理,支持BF16和FP8精度。
-
Nemotron 3 Nano在多个行业的AI代理开发中具有广泛应用潜力。
-
开发者可以从Hugging Face下载模型权重,进行定制和优化。
延伸解读
模型架构优势
Nemotron 3 Nano采用混合Mamba-Transformer MoE架构,能够在保持高准确率的同时,显著降低计算需求。这种设计使得模型在处理复杂任务时,能够实现更高的推理效率,适合需要快速响应的应用场景。
开源与定制化
该模型完全开源,开发者可以自由下载权重和数据集进行定制。这种开放性不仅提高了模型的透明度,还允许企业根据自身需求进行优化,确保在不同环境下的安全性和隐私保护。
行业应用潜力
Nemotron 3 Nano在多个基准测试中表现优异,适用于金融、网络安全、软件开发等多个行业。这使得它成为构建企业级AI代理的理想选择,能够满足多样化的业务需求。
延伸问答
Nemotron 3 Nano的架构是什么?
Nemotron 3 Nano采用混合Mamba-Transformer MoE架构。
Nemotron 3 Nano适合哪些应用场景?
Nemotron 3 Nano适用于金融、网络安全、软件开发和零售等多个行业的AI代理开发。
如何开始使用Nemotron 3 Nano进行推理?
可以从Hugging Face下载模型权重,并使用vLLM进行推理。
Nemotron 3 Nano的模型大小和参数数量是多少?
Nemotron 3 Nano的模型大小为30B,具有3B活跃参数。
Nemotron 3 Nano在基准测试中的表现如何?
Nemotron 3 Nano在多个基准测试中表现优异,如SWE Bench Verified和GPQA Diamond。
Nemotron 3 Nano支持哪些GPU?
Nemotron 3 Nano支持NVIDIA RTX Pro 6000、DGX Spark、H100和B200等GPU。
