
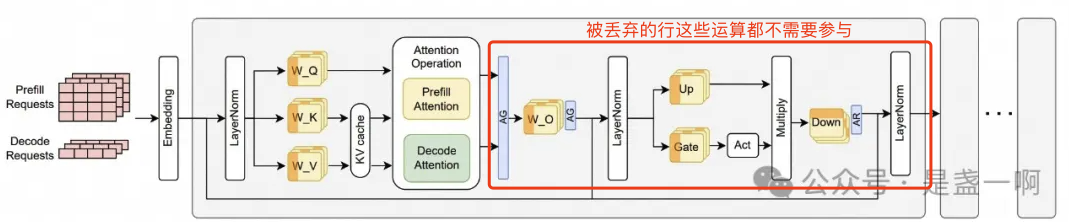
vllm 中的 sampling
内容提要
本文记录了对vllm 0.6.2源码的学习,重点介绍了vllm采样模块的数据结构与实现。采样过程根据模型输出的logits选择下一个token,涉及prefill和decode阶段的序列组。详细分析了SamplingMetadata的构建及其在采样中的应用,强调了prompt_logprobs功能的作用。
关键要点
-
vllm采样模块根据模型输出的logits选择下一个token,涉及prefill和decode阶段的序列组。
-
在prefill阶段,seq group的input prompt token会参与到采样中,尽管理论上不应参与。
-
prompt_logprobs功能会输出除第一个prompt token外的所有prompt token的预测概率及候选token id。
-
SamplingMetadata的构建包括seq_group_metadata_list、seq_lens和query_lens等信息。
-
sampling_input是经过selected_token_indices过滤后的model_output,包含需要处理的行。
-
每个seq group在model_output中对应着若干行,sample_len和prompt_logprob_len的关系在prefill和decode阶段有所不同。
-
采样实现通过Qwen2ForCausalLM.sample(logits, sampling_metadata)进行,logits对应sampling_input。
延伸解读
vllm采样模块的工作原理
vllm采样模块通过模型输出的logits选择下一个token,涉及prefill和decode两个阶段。在prefill阶段,尽管理论上不应参与采样,但由于prompt_logprobs功能的存在,部分input prompt token仍会被处理。这一设计使得模型在生成过程中能够更好地利用上下文信息。
SamplingMetadata的重要性
SamplingMetadata在vllm采样过程中扮演着关键角色。它包含了seq_group_metadata_list、seq_lens和query_lens等信息,帮助模型有效管理和处理不同的序列组。理解这些数据结构的构建和应用,有助于开发者优化采样过程,提高生成文本的质量。
prompt_logprobs功能的应用
prompt_logprobs功能允许模型输出除第一个prompt token外的所有token的预测概率及候选token id。这一功能不仅增强了模型的透明度,还为用户提供了更多的调试信息,帮助理解模型在生成过程中的决策依据。
延伸问答
vllm采样模块的主要功能是什么?
vllm采样模块根据模型输出的logits选择下一个token,涉及prefill和decode阶段的序列组。
什么是prompt_logprobs功能,它的作用是什么?
prompt_logprobs功能会输出除第一个prompt token外的所有prompt token的预测概率及候选token id。
SamplingMetadata的构建包含哪些信息?
SamplingMetadata的构建包括seq_group_metadata_list、seq_lens和query_lens等信息。
在prefill阶段,input prompt token如何参与采样?
在prefill阶段,seq group的input prompt token会参与到采样中,尽管理论上不应参与。
如何实现vllm的采样过程?
采样实现通过Qwen2ForCausalLM.sample(logits, sampling_metadata)进行,logits对应sampling_input。
vllm中sample_len和prompt_logprob_len的关系是什么?
对于prefill seq group,sample_len和prompt_logprob_len的和等于query_len;对于decode seq group,prompt_logprob_len为0。
