
F2LLM-v2开源:让语言不再是障碍,让AI触手可及
内容提要
F2LLM-v2是蚂蚁集团与上海交通大学联合开源的嵌入模型,旨在解决语言偏见和透明度问题。该模型支持282种语言,尤其在多语言和代码搜索方面表现优异,提供多种尺寸以满足不同需求,推动开源社区发展。
关键要点
-
F2LLM-v2是蚂蚁集团与上海交通大学联合开源的嵌入模型,旨在解决语言偏见和透明度问题。
-
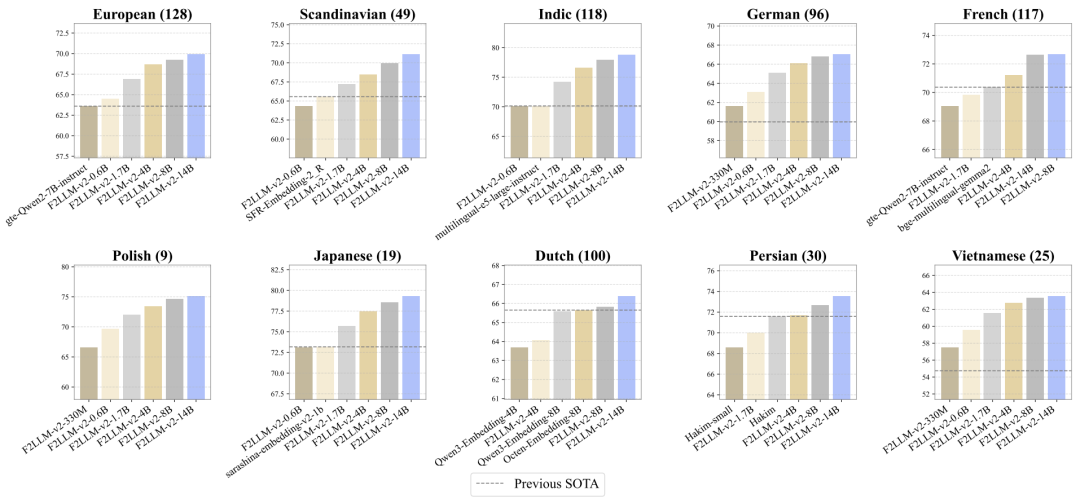
该模型支持282种语言,尤其在多语言和代码搜索方面表现优异。
-
F2LLM-v2提供多种尺寸以满足不同需求,从80M到14B,适应不同场景。
-
模型的训练数据全部来自公开资源,团队公开了完整的训练配方和相关代码,体现了开源透明的精神。
-
F2LLM-v2在MTEB评测中表现出色,刷新了多项SOTA记录,成为开发者构建智能化代码库检索的首选。
-
所有模型均支持套娃式表征,提供灵活的存储成本和检索速度的权衡空间。
-
F2LLM-v2代表了开源社区的力量,推动了更包容、更透明的AI世界的构建。
延伸解读
开源透明度的重要性
F2LLM-v2的开源特性不仅提供了完整的训练数据和代码,还促进了研究者的复现能力。这种透明度有助于推动AI领域的创新,尤其是在多语言处理和代码搜索方面,开发者可以在此基础上进行更深入的研究和应用开发。
多语言支持的实际应用
F2LLM-v2支持282种语言,尤其在中低资源语言上表现出色。这使得其在全球范围内的应用潜力巨大,尤其适合需要多语言处理的企业和开发者,能够帮助他们更好地服务于多样化的用户群体。
模型尺寸的灵活性
F2LLM-v2提供从80M到14B的多种模型尺寸,适应不同的应用场景。小尺寸模型在保持高性能的同时,显著提升了推理效率,为开发者在存储成本和速度之间提供了灵活的选择,这对于资源有限的项目尤为重要。
延伸问答
F2LLM-v2的主要目标是什么?
F2LLM-v2旨在解决语言偏见和透明度问题,推动多语言和代码搜索的应用。
F2LLM-v2支持多少种语言?
F2LLM-v2支持282种语言,包括多种编程语言。
F2LLM-v2在MTEB评测中的表现如何?
F2LLM-v2在MTEB评测中表现出色,刷新了多项SOTA记录,尤其在多语言和代码搜索方面。
F2LLM-v2提供哪些模型尺寸?
F2LLM-v2提供从80M到14B的多种尺寸,以满足不同应用场景的需求。
F2LLM-v2的训练数据来源是什么?
F2LLM-v2的训练数据全部来自公开资源,团队公开了完整的训练配方和相关代码。
F2LLM-v2如何促进开源社区的发展?
F2LLM-v2通过提供透明的训练数据和代码,推动了更包容和透明的AI世界的构建。
