
Qwen2.5的小小部署测试
内容提要
阿里新开源的Qwen2.5模型推出了多种参数尺寸,72B模型在多个任务中表现优异,超越了GPT-4o-mini。该模型支持商业使用,适合多种设备,量化后可在家用卡上运行,整体性能提升显著,推荐在公司服务器上使用。
关键要点
-
阿里新开源的Qwen2.5模型推出了7种参数尺寸,包括72B、32B等。
-
72B模型在多个任务中表现优异,超越了GPT-4o-mini。
-
32B模型在大部分测试项目中也超过了GPT-4o-mini。
-
Qwen2.5模型支持商业使用,除了3B和72B外,其他模型均为Apache 2.0许可。
-
经过量化后,Qwen2.5模型可以在家用显卡上运行,性能显著提升。
-
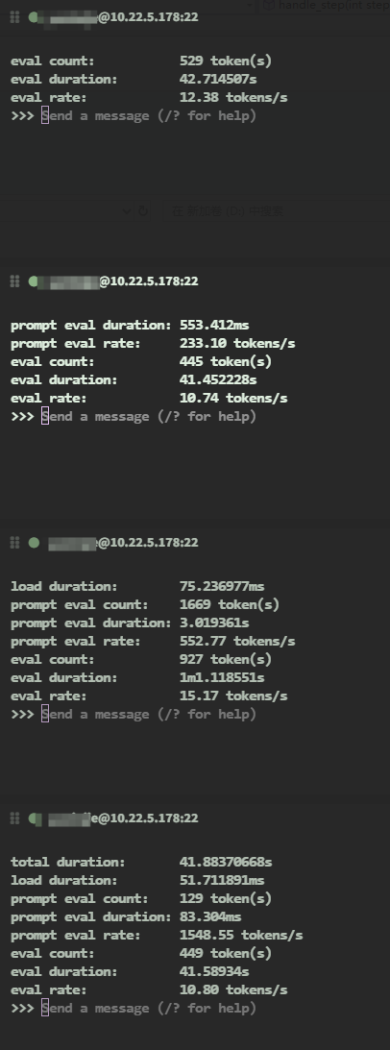
推荐在公司服务器上使用Qwen2.5模型,尤其是32B版本,能够达到160-200t/s的速度。
延伸解读
模型参数选择的重要性
Qwen2.5提供了多种参数尺寸的模型,用户在选择时应考虑具体应用场景。72B模型在性能上表现优异,但对于资源有限的用户,32B模型同样在大部分任务中超越了GPT-4o-mini,适合中小型企业使用。
量化后的性能优势
经过量化的Qwen2.5模型可以在家用显卡上运行,显著降低了硬件要求。这使得更多用户能够以较低成本体验高性能的AI模型,尤其是对于教育和小型开发团队来说,具有重要的实用价值。
商业使用许可的灵活性
Qwen2.5模型的商业使用许可为企业提供了灵活性,除了3B和72B外,其他模型均为Apache 2.0许可。这意味着企业可以根据需求自由选择和部署模型,降低了使用门槛,促进了技术的普及。
延伸问答
Qwen2.5模型有哪些参数尺寸?
Qwen2.5模型推出了7种参数尺寸,包括0.5B、1.5B、3B、7B、14B、32B和72B。
Qwen2.5的72B模型与GPT-4o-mini相比表现如何?
72B模型在多个任务中表现优异,超越了GPT-4o-mini。
Qwen2.5模型是否支持商业使用?
Qwen2.5模型支持商业使用,除了3B和72B外,其他模型均为Apache 2.0许可。
Qwen2.5模型经过量化后能在什么设备上运行?
经过量化后,Qwen2.5模型可以在家用显卡上运行,性能显著提升。
推荐在什么环境下使用Qwen2.5模型?
推荐在公司服务器上使用Qwen2.5模型,尤其是32B版本,能够达到160-200t/s的速度。
Qwen2.5模型的测试结果在哪里可以查看?
测试结果可以在官方页面 https://qwenlm.github.io/blog/qwen2.5-llm/ 查看。
