
微软 AI 推出 Phi-4:全新 140 亿参数小型语言模型,专攻复杂推理
内容提要
微软研究院开发的Phi-4模型拥有140亿参数,通过合成数据和训练后优化技术,在推理任务中表现优于GPT-4和Llama-3,展示了小型模型的潜力。该模型强调高质量数据和有效训练,解决了大型语言模型面临的高计算成本和数据集多样性不足的问题。
关键要点
-
大型语言模型在自然语言理解和推理任务中取得了显著进展,但面临高计算成本和数据集多样性不足的问题。
-
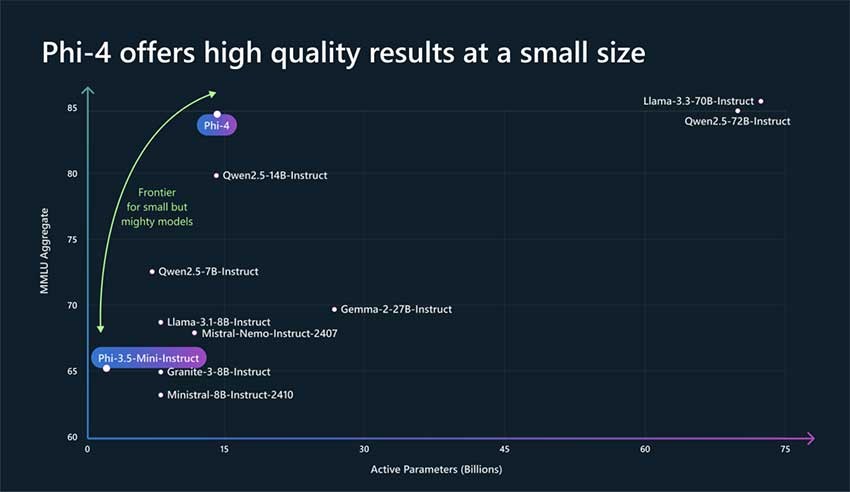
微软研究院开发的Phi-4模型拥有140亿参数,旨在提供更小、更高效的解决方案。
-
Phi-4采用合成数据生成、课程设计和训练后优化的新方法,能够与GPT-4和Llama-3等大型模型竞争。
-
模型训练依赖高质量的合成数据,确保其在推理任务中遇到多样化和结构化的场景。
-
训练后技术如拒绝采样和直接偏好优化(DPO)提高了模型的准确性和可用性。
-
Phi-4的上下文长度从4K增加到16K个token,增强了其处理长链推理任务的能力。
-
在多个基准测试中,Phi-4的表现优于GPT-4o和Llama-3,显示出其在推理密集型任务中的优势。
-
Phi-4在编码基准测试HumanEval中得分82.6,并在现实世界数学竞赛中表现优异,证明其实用性。
-
Phi-4的设计强调效率和推理能力,展示了较小模型也能实现与大型模型相当的结果。
-
随着人工智能的发展,Phi-4等模型展示了针对性创新在克服技术挑战中的重要性。
延伸解读
小型模型的优势
Phi-4模型的推出表明,小型语言模型在推理任务中能够与大型模型竞争,尤其是在计算成本和资源利用方面。通过优化训练方法和使用合成数据,Phi-4展示了在保持高效性的同时,仍能实现强大的推理能力。这为未来的AI应用提供了新的思路,尤其是在资源受限的环境中。
合成数据的重要性
Phi-4的成功依赖于高质量的合成数据,这些数据通过多智能体提示和指令反转等技术生成。这种方法不仅提高了模型的训练效果,还确保了其在复杂推理任务中的表现。未来,合成数据的使用可能会成为提升模型性能的关键策略,值得研究者关注。
训练后优化技术的应用
Phi-4采用了拒绝采样和直接偏好优化(DPO)等训练后技术,这些技术显著提高了模型的准确性和可用性。这表明,后训练优化在提升模型性能方面具有重要作用,未来的模型设计可以借鉴这一思路,以实现更高的推理能力和用户体验。
延伸问答
Phi-4模型的主要特点是什么?
Phi-4模型拥有140亿参数,采用合成数据生成、课程设计和训练后优化的新方法,能够有效处理推理任务。
Phi-4如何解决大型语言模型的计算成本问题?
Phi-4通过采用小型模型设计和高效的训练方法,显著降低了计算成本,同时保持了强大的推理能力。
Phi-4在推理任务中的表现如何?
在多个基准测试中,Phi-4的表现优于GPT-4和Llama-3,特别是在推理密集型任务中显示出优势。
Phi-4使用了哪些训练技术来提高准确性?
Phi-4使用了拒绝采样和直接偏好优化(DPO)等训练后技术,以提高模型的响应准确性和可用性。
Phi-4的上下文长度有什么变化?
Phi-4的上下文长度从4K增加到16K个token,增强了其处理长链推理任务的能力。
Phi-4在实际应用中表现如何?
Phi-4在HumanEval编码基准测试中得分82.6,并在现实世界数学竞赛中表现优异,证明了其实用性。
