

💡
原文中文,约2000字,阅读约需5分钟。
📝
内容提要
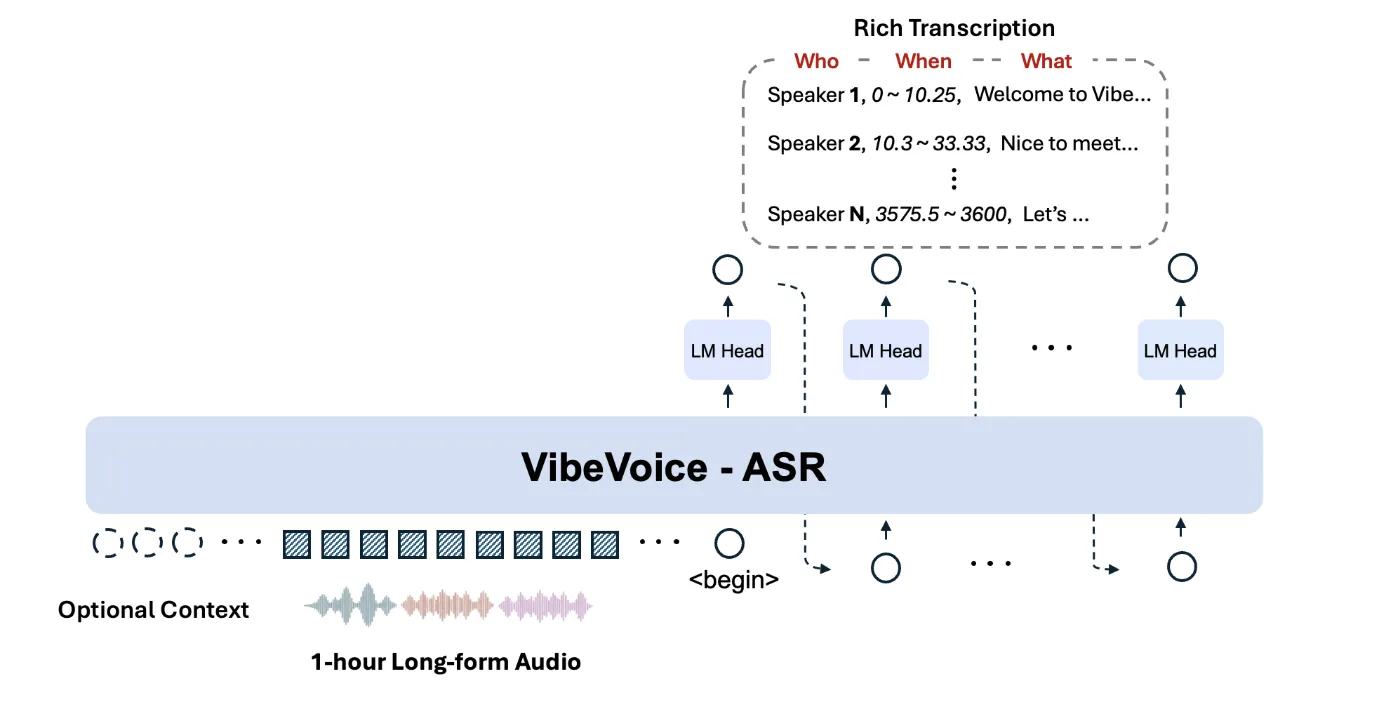
微软推出了VibeVoice-ASR,一个开源的语音转文本模型,支持最长60分钟的音频处理,输出结构化文本,包括“谁”、“何时”、“什么”。该模型允许用户自定义热词,以提高识别准确性,适合会议记录和长时间通话。
🎯
关键要点
- 微软推出了VibeVoice-ASR,一个开源的语音转文本模型。
- 该模型支持最长60分钟的音频处理,输出结构化文本,包括“谁”、“何时”、“什么”。
- VibeVoice-ASR允许用户自定义热词,以提高识别准确性,适合会议记录和长时间通话。
- 模型在64K标记长度预算内接收长达60分钟的连续音频输入,保持说话人身份和主题上下文。
- 自定义热词功能使用户能够针对特定领域调整识别过程,无需重新训练模型。
- 模型联合执行自动语音识别、人声分割和时间戳功能,返回结构化输出。
- 使用DER、cpWER和tcpWER评估模型在多说话人长篇数据上的表现。
- VibeVoice-ASR在VibeVoice开源堆栈中以MIT许可证发布,附带官方权重和微调脚本。
➡️
