
深入探讨Cloudflare的万亿消息Kafka基础设施
内容提要
Cloudflare的Kafka基础设施最近达到了处理1万亿条消息的里程碑。Cloudflare自2014年以来一直在使用Kafka,目前运行着14个Kafka集群。他们最初使用Kafka来解耦服务并启用重试机制。为了强制执行消息合同,Cloudflare采用了Protocol Buffers(Protobuf)。他们还开发了一个内部的Go消息总线客户端库,以简化Kafka的使用。Cloudflare的应用服务团队开发了一个连接器框架,以抽象常见模式并简化数据同步流水线。Cloudflare在Kafka采用过程中面临了扩展挑战,包括可见性、嘈杂的值班体验以及无法跟上高消息产生速率。他们通过增强SDK的Prometheus指标、实施健康检查和引入批量消费来解决这些挑战。Cloudflare的经验为在配置和简化之间取得平衡、确保分布式系统的可见性以及建立生产者和消费者之间的明确合同提供了宝贵的教训。
关键要点
-
Cloudflare的Kafka基础设施最近达到了处理1万亿条消息的里程碑。
-
Cloudflare自2014年以来一直在使用Kafka,当前运行着14个Kafka集群。
-
最初使用Kafka是为了解耦服务并启用重试机制。
-
Cloudflare采用Protocol Buffers(Protobuf)来强制执行消息合同。
-
开发了一个内部的Go消息总线客户端库,以简化Kafka的使用。
-
应用服务团队开发了连接器框架,以抽象常见模式并简化数据同步流水线。
-
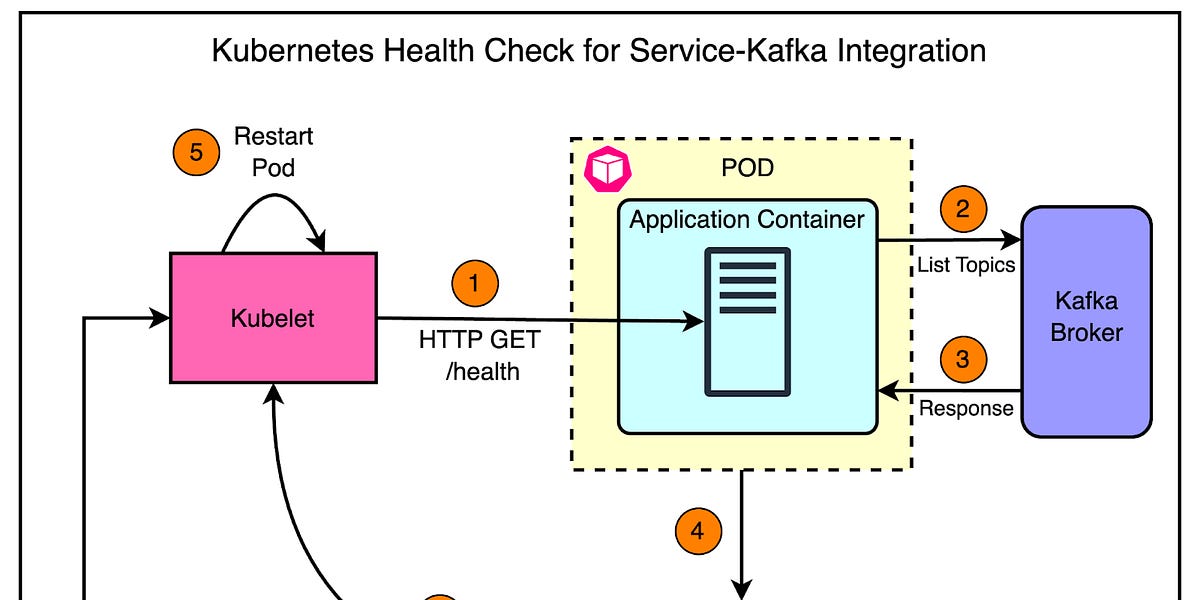
Cloudflare在Kafka采用过程中面临扩展挑战,包括可见性和嘈杂的值班体验。
-
通过增强SDK的Prometheus指标和实施健康检查来解决可见性问题。
-
引入批量消费来提高邮件系统的处理能力,解决无法跟上高消息产生速率的问题。
-
Cloudflare的经验为确保分布式系统的可见性和建立生产者与消费者之间的明确合同提供了宝贵的教训。
延伸问答
Cloudflare的Kafka基础设施达到了什么里程碑?
Cloudflare的Kafka基础设施最近达到了处理1万亿条消息的里程碑。
Cloudflare为什么选择使用Kafka?
Cloudflare选择使用Kafka是为了解耦服务并启用重试机制。
Cloudflare如何解决Kafka扩展过程中的可见性问题?
Cloudflare通过增强SDK的Prometheus指标和实施健康检查来解决可见性问题。
Cloudflare在Kafka中使用了什么技术来强制执行消息合同?
Cloudflare采用了Protocol Buffers(Protobuf)来强制执行消息合同。
Cloudflare是如何简化Kafka使用的?
Cloudflare开发了一个内部的Go消息总线客户端库,以简化Kafka的使用。
Cloudflare在Kafka采用过程中面临了哪些挑战?
Cloudflare面临的挑战包括可见性、嘈杂的值班体验和无法跟上高消息产生速率。
