

大型语言模型评估指南
💡
原文英文,约2100词,阅读约需8分钟。
📝
内容提要
安全授权MCP服务器访问复杂,涉及PKCE、范围、同意流程及撤销访问的方法。LLM评估面临概率性挑战,需要系统化评估方法。自动与人工评估各有优缺点,应结合使用。建立评估流程并定期迭代,以确保模型性能。
🎯
关键要点
- 安全授权MCP服务器访问复杂,涉及PKCE、范围、同意流程及撤销访问的方法。
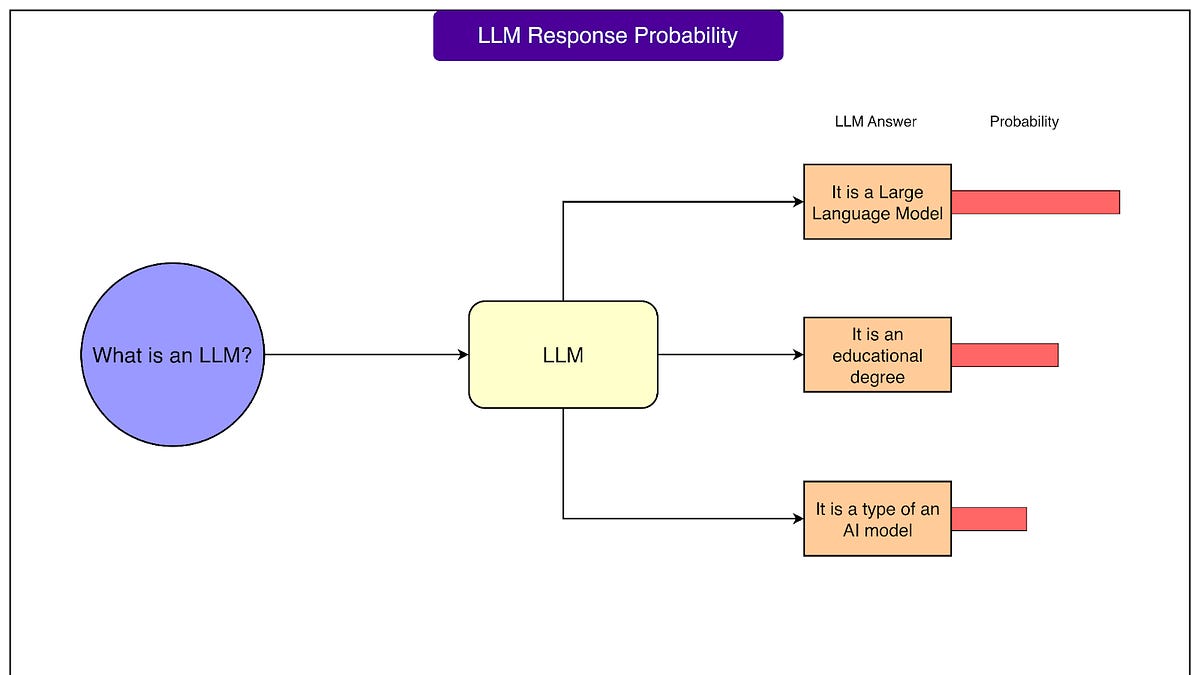
- 大语言模型(LLM)从研究实验室迅速进入生产应用,但评估其性能面临挑战。
- LLM的评估需要系统化的方法,传统软件测试方法不完全适用。
- 评估方法包括自动评估、人工评估和基准评估,各有优缺点。
- 自动评估可以快速检测明显错误,但可能错过细微问题。
- 人工评估是评估LLM性能的金标准,能判断主观质量。
- 基准评估提供可比性,但可能不反映特定用例的性能。
- 建立有效评估需要理解评估指标、评估数据集和统计考虑。
- 设置评估流程时,应定义成功标准、创建初始评估集并选择评估方法。
- 常见的陷阱包括过拟合评估集、游戏化指标和忽视边缘案例。
- LLM评估应成为开发工作流的一部分,以确保模型性能和安全性。
➡️
