

评估自主系统的伦理问题
MIT News - Artificial intelligence
·
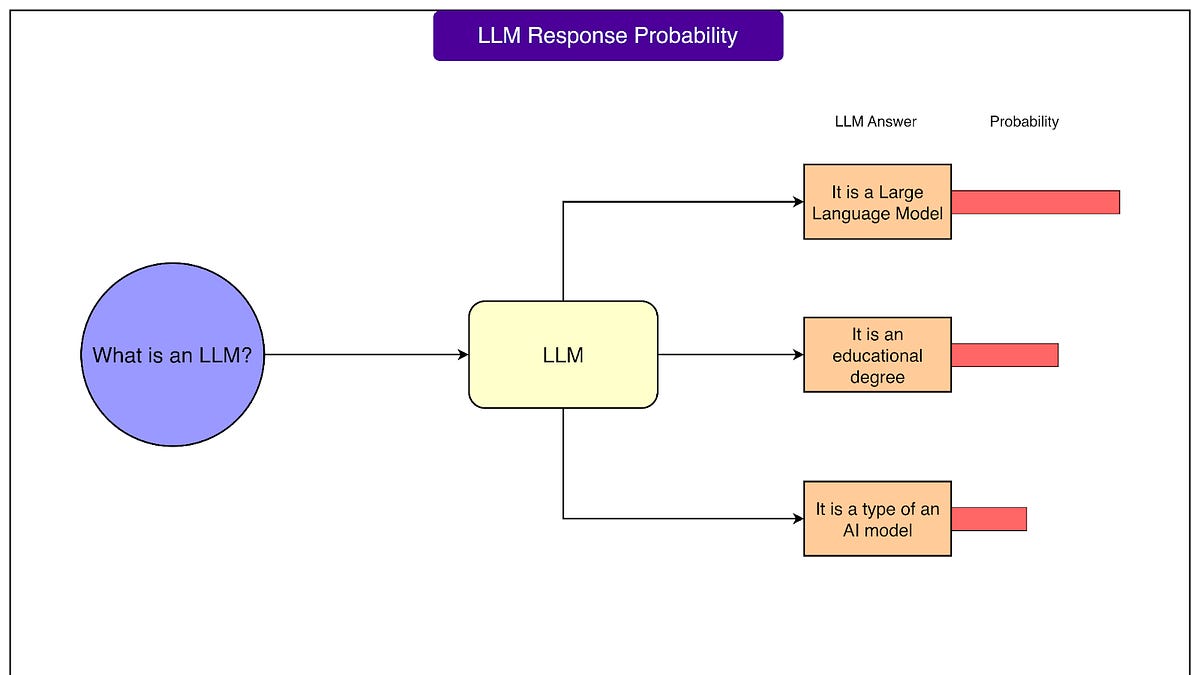
大型语言模型评估指南
ByteByteGo Newsletter
·

谁来监督监督者?大型语言模型对大型语言模型的评估
Stack Overflow Blog
·

生成性与预测性人工智能在应用安全中的全面概述
DEV Community
·

应用安全中生成性与预测性人工智能的全面指南
DEV Community
·


🧠 利用GenAI自动评估聊天机器人:流程、提示与证据
DEV Community
·

🧠 利用生成性人工智能评估聊天机器人:问题、潜力与计划
DEV Community
·

应用安全中生成性和预测性人工智能的全面指南
DEV Community
·

