
Databricks如何实现智能Kubernetes负载均衡
内容提要
AI面临的主要挑战之一是记忆,影响模型的上下文保持和一致性。Databricks团队通过优化Kubernetes流量管理和客户端负载均衡系统,提高资源利用率和降低延迟,实现更智能的请求路由。
关键要点
-
AI面临的主要挑战之一是记忆,影响模型的上下文保持和一致性。
-
Databricks团队通过优化Kubernetes流量管理和客户端负载均衡系统,提高资源利用率和降低延迟。
-
短期、长期和持久记忆在智能体性能中的作用至关重要。
-
Kubernetes成为现代微服务的标准平台,但在高流量和低延迟场景下存在局限性。
-
Databricks面临流量不均、可扩展性差和高尾延迟等问题。
-
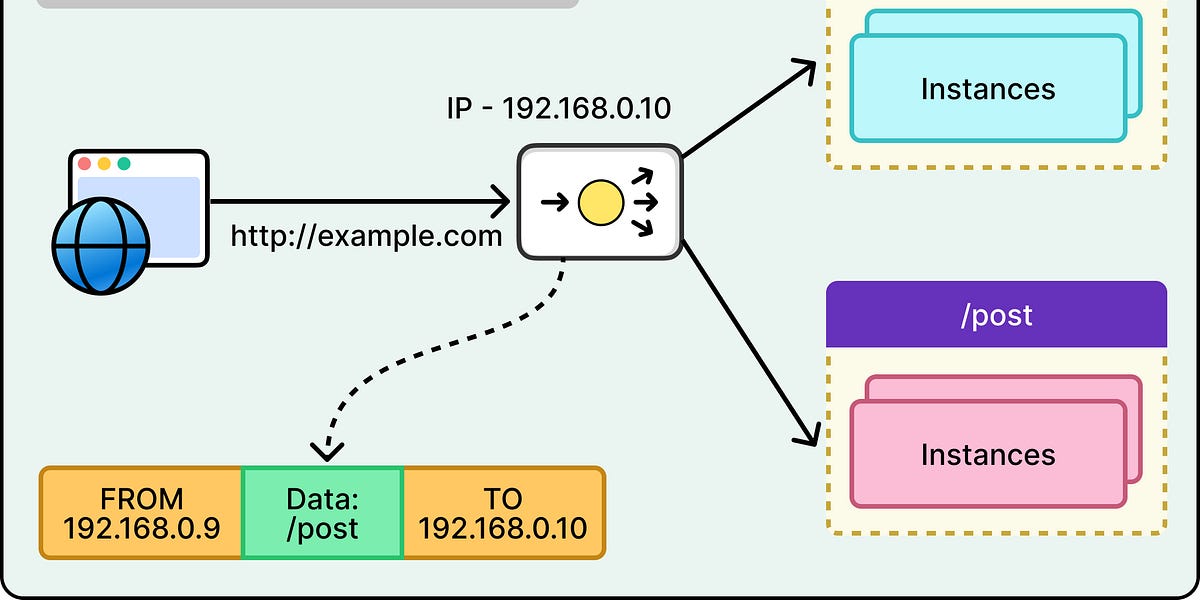
Databricks团队开发了一个客户端负载均衡系统,实时监控服务状态,优化请求路由。
-
自定义控制平面负责实时服务发现,提供健康的端点信息。
-
集成RPC框架使得负载均衡逻辑易于应用团队采用,减少了操作开销。
-
客户端负载均衡系统支持更灵活的路由策略,如双选择算法和区域亲和路由。
-
Databricks将智能负载均衡扩展到外部流量,确保内部和外部流量的一致性。
-
新的负载均衡系统提高了资源利用率,降低了延迟,改善了性能。
-
未来,Databricks计划实现跨集群和跨区域的负载均衡,支持更大规模的工作负载。
延伸解读
智能负载均衡的必要性
在高流量和低延迟的场景中,传统的Kubernetes负载均衡存在明显局限,导致流量分配不均和高尾延迟。Databricks通过开发客户端负载均衡系统,实时监控服务状态,优化请求路由,从而提高了资源利用率和系统性能。
灵活的路由策略
Databricks的新负载均衡系统支持多种灵活的路由策略,如双选择算法和区域亲和路由。这种灵活性使得系统能够根据实时数据做出更智能的路由决策,避免了传统方法的流量峰值和资源浪费问题。
未来的扩展计划
Databricks计划在未来实现跨集群和跨区域的负载均衡,以支持更大规模的工作负载。这一扩展将使其平台能够更好地应对AI重负载应用的需求,同时保持高可靠性。
延伸问答
Databricks如何解决Kubernetes负载均衡的问题?
Databricks通过开发客户端负载均衡系统,将负载均衡责任从基础设施层转移到客户端,实时监控服务状态,优化请求路由。
Kubernetes在高流量场景下存在哪些局限性?
Kubernetes在高流量和低延迟场景下存在流量不均、可扩展性差和高尾延迟等问题。
Databricks的客户端负载均衡系统有哪些优势?
该系统提供更均匀的流量分配、降低延迟和更好的资源利用率,支持灵活的路由策略。
什么是Power of Two Choices算法?
Power of Two Choices算法随机选择两个健康的端点,并将请求发送到负载较轻的那个,从而避免流量峰值和过载。
Databricks如何实现实时服务发现?
Databricks通过自定义控制平面监控Kubernetes资源,实时更新服务状态并提供给客户端。
未来Databricks在负载均衡方面有哪些计划?
Databricks计划实现跨集群和跨区域的负载均衡,支持更大规模的工作负载,并探索AI感知的负载均衡策略。
