
VLM2Vec-V2:用于跨图像、视频和视觉文档进行多模态嵌入学习的统一计算机视觉框架
内容提要
VLM2Vec-V2是一种新型多模态嵌入模型,旨在统一图像、视频和视觉文档检索。基于MMEB-V2基准,支持多种输入模态,采用Qwen2-VL作为骨干,具备动态分辨率和多模态嵌入特性,提升了对比学习的稳定性。实验结果表明,该模型在多模态任务中表现优异。
关键要点
-
VLM2Vec-V2是一种新型多模态嵌入模型,旨在统一图像、视频和视觉文档检索。
-
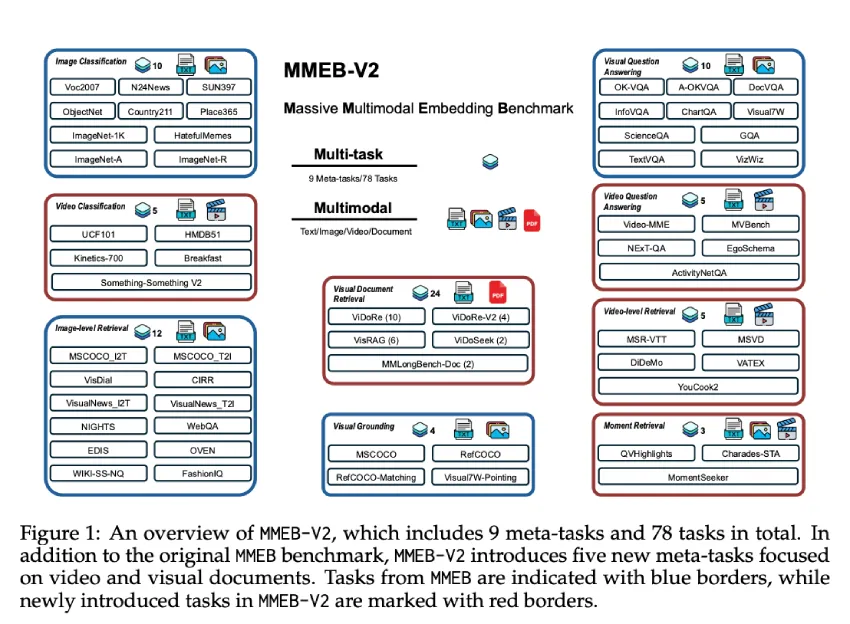
现有多模态嵌入模型主要基于MMEB和M-BEIR等数据集,关注静态图像,无法涵盖更广泛的视觉信息。
-
VLM2Vec-V2通过MMEB-V2基准扩展了五种新任务类型,包括视觉文档检索和视频分类。
-
该模型采用Qwen2-VL作为骨干架构,具备动态分辨率和多模态嵌入特性。
-
VLM2Vec-V2引入灵活的数据采样流程,提高对比学习的稳定性。
-
在78个数据集中,VLM2Vec-V2获得了58.0的最高总平均分,超越了多个基线模型。
-
尽管参数规模仅为2B,VLM2Vec-V2在图像任务中的表现与VLM2Vec-7B相当。
-
在视觉文档检索方面,VLM2Vec-V2的表现优于所有变体,但仍落后于ColPali。
-
VLM2Vec-V2建立在MMEB-V2之上,证明了其在跨多种模态实现均衡性能的有效性。
延伸解读
多模态嵌入的必要性
随着信息的多样化,传统的多模态嵌入模型往往局限于静态图像,无法满足实际应用需求。VLM2Vec-V2通过整合图像、视频和视觉文档,填补了这一空白,提升了检索的全面性和准确性。
对比学习的稳定性提升
VLM2Vec-V2引入了灵活的数据采样流程,显著提高了对比学习的稳定性。这一创新使得模型在多任务训练中表现更为出色,尤其是在处理不同模态的数据时,能够有效减少训练过程中的波动。
性能与参数规模的关系
尽管VLM2Vec-V2的参数规模仅为2B,但其在图像任务中的表现与更大规模的模型相当。这表明,模型的设计和架构优化在性能提升中起到了关键作用,未来的研究可以借鉴这一思路。
视觉文档检索的挑战
尽管VLM2Vec-V2在视觉文档检索方面表现优于其他变体,但仍未能超越专门优化的ColPali。这提示研究者在未来的模型开发中,需针对特定任务进行更深入的优化,以提升整体性能。
延伸问答
VLM2Vec-V2的主要功能是什么?
VLM2Vec-V2是一种多模态嵌入模型,旨在统一图像、视频和视觉文档的检索。
VLM2Vec-V2与现有模型相比有什么优势?
VLM2Vec-V2在多模态任务中表现优异,且在78个数据集中获得了58.0的最高总平均分,超越多个基线模型。
VLM2Vec-V2是如何提高对比学习的稳定性的?
VLM2Vec-V2引入了灵活的数据采样流程,包括动态批次混合和交错子批次策略,以提高对比学习的稳定性。
VLM2Vec-V2使用了什么样的骨干架构?
VLM2Vec-V2采用Qwen2-VL作为骨干架构,因其在多模态处理方面的专业能力而被选中。
VLM2Vec-V2支持哪些输入模态?
VLM2Vec-V2支持图像、视频和视觉文档等多种输入模态。
VLM2Vec-V2在视觉文档检索方面的表现如何?
VLM2Vec-V2在视觉文档检索方面的表现优于所有变体,但仍落后于专门优化的ColPali。
