
记忆和向量-读《图解大模型》
内容提要
记忆大模型无状态,短期记忆通过对话缓冲区和摘要实现。RAG利用知识库解决知识过时问题,文档向量化和长文本分块策略至关重要。有效分块需提取重点,结合单文档和多向量策略,以优化搜索效果。
关键要点
-
记忆大模型是无状态,不会记住先前对话内容。
-
短期记忆通过对话缓冲区和对话摘要实现。
-
对话缓冲区使用ConversationBufferMemory和ConversationBufferWindowMemory。
-
对话摘要用于将历史对话转为摘要,依赖LLM参与。
-
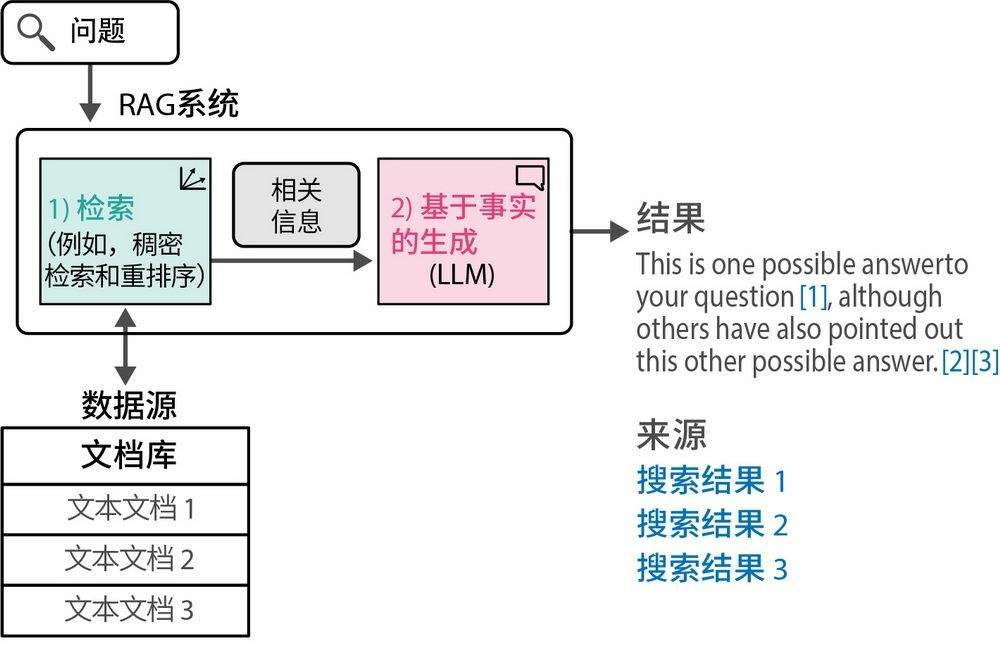
RAG通过知识库解决LLM知识过时和缺乏专业知识的问题。
-
文档向量化是将分块转化为向量表示,存储在向量数据库中。
-
长文本分块策略面临LLM的tokens上限挑战。
-
单文档单向量和单文档多向量是解决分块问题的两种思路。
-
有效的分块需提取代表性段落,过滤低质内容。
-
结合单文档提取和多向量分块策略以优化搜索效果。
-
创新的分块策略正在利用LLM实现动态智能分块。
延伸解读
短期记忆的实现方式
文章提到短期记忆主要通过对话缓冲区和对话摘要来实现。对话缓冲区的使用可以有效管理对话内容,但需注意控制上限以避免信息丢失。对话摘要则通过LLM生成,帮助提炼重要信息,确保对话的连贯性和有效性。
RAG与知识库的结合
RAG模型通过知识库解决了大模型在知识更新和专业性方面的不足。结合文档向量化和长文本分块策略,可以提高信息检索的效率。理解这些技术的结合方式,有助于在实际应用中优化搜索效果。
分块策略的挑战与解决方案
长文本的分块策略面临LLM的tokens上限挑战。文章提出了单文档单向量和单文档多向量两种思路,强调在分块过程中提取代表性段落的重要性。这些策略的有效结合将有助于提升信息检索的准确性和效率。
延伸问答
记忆大模型是如何实现短期记忆的?
记忆大模型通过对话缓冲区和对话摘要实现短期记忆。
RAG在大模型中有什么作用?
RAG通过知识库解决了大模型知识过时和缺乏专业知识的问题。
文档向量化的过程是怎样的?
文档向量化是将分块转化为向量表示,并存储在向量数据库中以备检索。
长文本分块策略面临哪些挑战?
长文本分块策略面临LLM的tokens上限挑战。
如何优化搜索效果?
通过结合单文档提取和多向量分块策略,可以优化搜索效果。
对话摘要的作用是什么?
对话摘要用于将历史对话转为摘要,以解决对话缓冲区内容过多的问题。
