

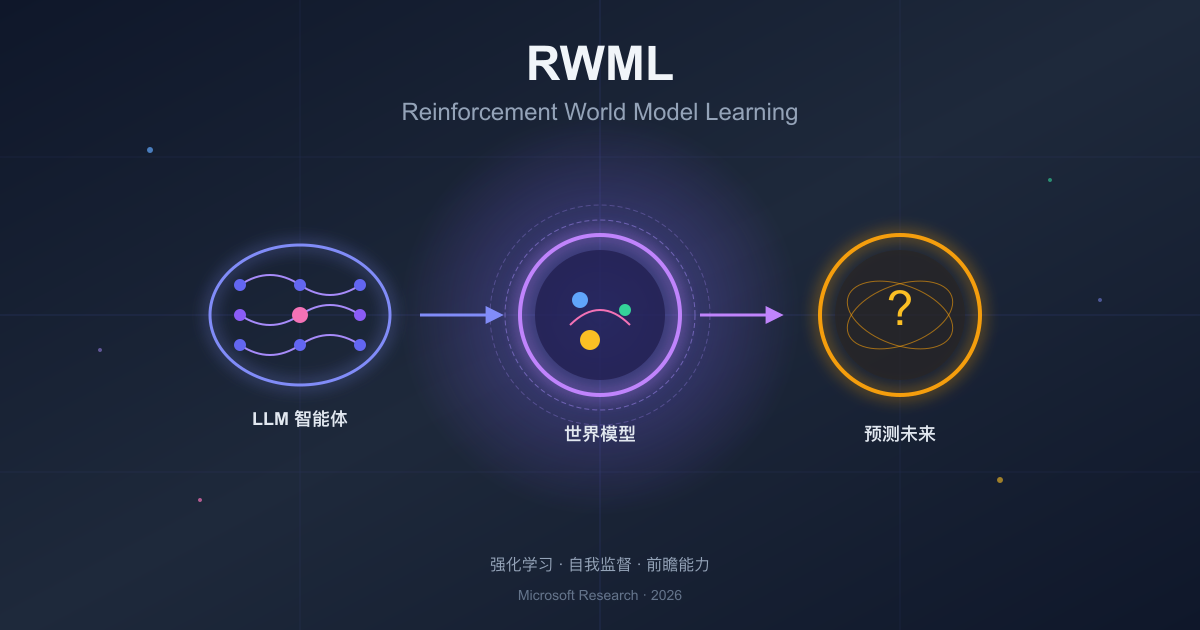
RWML:让 LLM 智能体学会预测未来——微软研究院突破性论文解读
💡
原文中文,约2500字,阅读约需6分钟。
📝
内容提要
本文介绍了RWML(强化世界模型学习),一种新方法,使大语言模型(LLM)能够预测行动后果。通过强化学习,RWML显著提升了智能体在复杂环境中的表现,减少了灾难性遗忘,开辟了LLM训练的新方向。
🎯
关键要点
- RWML(强化世界模型学习)是一种新方法,使大语言模型(LLM)能够预测行动后果。
- LLM智能体在复杂环境中缺乏前瞻能力,无法预测行动的后果。
- RWML通过强化学习训练世界模型,而非传统的监督学习(SFT)。
- RWML的训练流程分为两个阶段:世界模型学习和策略强化学习。
- RWML在多个基准测试中表现优异,成功率显著提升。
- RWML比传统SFT方法导致更少的灾难性遗忘,保留原有知识更好。
- RWML为LLM智能体的训练开辟了新方向,具备世界建模能力的智能体能更好地规划和决策。
- RWML可能成为LLM智能体训练的标准步骤,提升数据效率。
➡️
