
生成式人脸图像压缩与压缩域视觉任务分析 | TCSVT 2024
内容提要
本论文提出了一种分层端到端人脸图像编码模型,能够在高压缩比下提供高质量的人脸图像重建,并支持多种视觉分析任务。通过联合优化和基于压缩域的多任务分析,模型能够在大幅降低比特率的同时,保持与RGB图像相当的分析效果和重建质量。实验结果证明了该模型的实用性和有效性。
关键要点
-
本论文提出了一种分层端到端人脸图像编码模型,能够在高压缩比下提供高质量的人脸图像重建。
-
该模型支持多种视觉分析任务,通过联合优化和基于压缩域的多任务分析,保持与RGB图像相当的分析效果和重建质量。
-
实验结果证明该模型在节省99.6%比特率的同时,能够保证重建图像的感知质量。
-
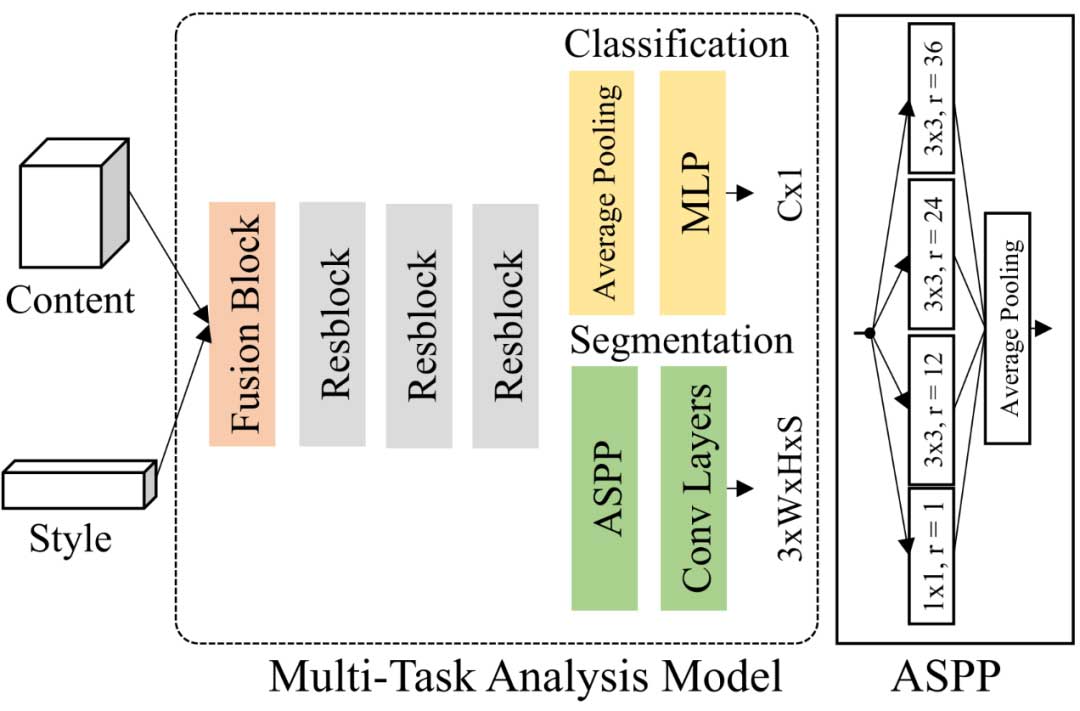
模型包括分层编码器、解码器和概率估计模型,采用不同编码器分别支持重建和语义分析。
-
训练策略分为面向人类视觉任务和面向机器感知任务,采用多种失真度量以满足人眼视觉需求。
-
基于压缩域的多任务分析网络通过联合训练与独立训练两种模式进行优化,探索压缩与机器视觉感知之间的关系。
-
实验结果显示多任务分析网络在分析感知任务上有正向作用,提升了准确度。
-
本论文的模型在高压缩率下显示出视觉分析性能的提升与重建图像质量之间的权衡关系。
-
总结指出该模型在人脸图像数据上验证了压缩域表征的有效性,支持多种下游视觉分析任务,具有实用价值。
延伸问答
该论文提出了什么样的人脸图像编码模型?
该论文提出了一种分层端到端人脸图像编码模型,能够在高压缩比下提供高质量的人脸图像重建。
该模型如何支持视觉分析任务?
该模型通过联合优化和基于压缩域的多任务分析,能够保持与RGB图像相当的分析效果和重建质量。
实验结果显示该模型在比特率节省方面的表现如何?
实验结果证明该模型在节省99.6%比特率的同时,能够保证重建图像的感知质量。
模型的训练策略有哪些?
训练策略分为面向人类视觉任务和面向机器感知任务,采用多种失真度量以满足人眼视觉需求。
多任务分析网络的优势是什么?
多任务分析网络在分析感知任务上有正向作用,提升了准确度。
该模型在视觉分析性能与重建图像质量之间有什么关系?
该模型在高压缩率下显示出视觉分析性能的提升与重建图像质量之间的权衡关系。
