
飞桨实现插件式硬件图接入方案,模型推理加速2.2倍
内容提要
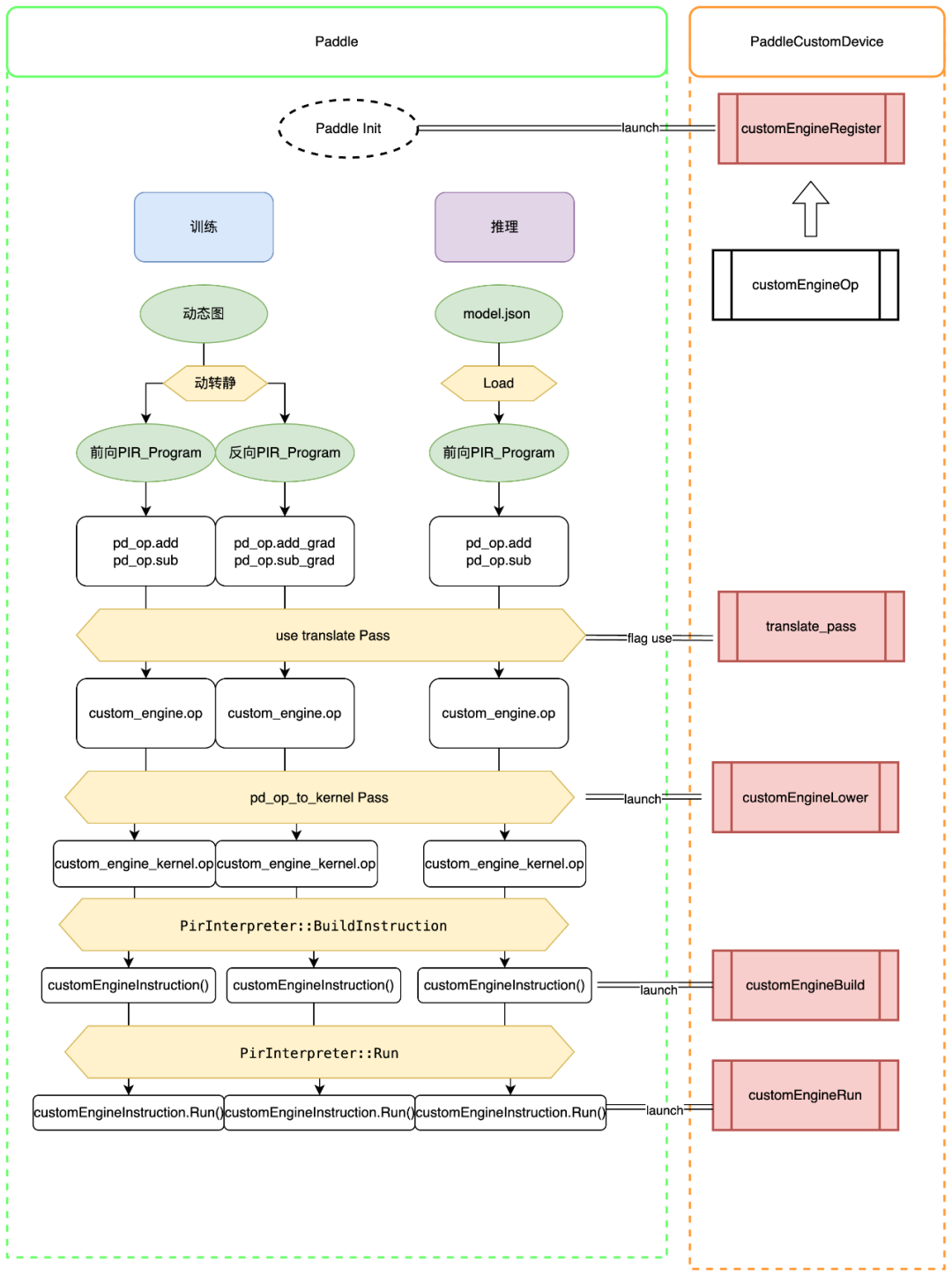
飞桨框架3.0版本推出了多硬件统一适配方案,采用“分层解耦、多元接入”设计理念,显著降低硬件适配成本。插件式架构使硬件厂商灵活接入,提升模型训练和推理性能。例如,燧原GCU的图优化方案使推理速度提升2.2倍,减少CPU调度开销,持续优化将扩展更多应用场景。
关键要点
-
飞桨框架3.0版本推出了多硬件统一适配方案,采用“分层解耦、多元接入”设计理念。
-
通过硬件接口抽象,降低硬件适配成本,适配代码量减少80%。
-
插件式架构设计实现“即插即用”的硬件接入模式,简化接入流程。
-
飞桨提供多种接入方式,涵盖算子开发、算子映射、图接入等。
-
与芯片厂商建立协同创新模式,保障技术演进和质量根基。
-
燧原GCU通过图优化方案使推理速度提升2.2倍,减少CPU调度开销。
-
硬件厂商可灵活实现功能分离,降低与飞桨协同开发的成本。
-
子图机制将多个OP融合为一个OP,减少CPU启动硬件kernel的次数。
-
后续可基于图执行机制扩展更多应用场景,进行持续优化。
延伸解读
多硬件适配的优势
飞桨框架3.0通过“分层解耦、多元接入”的设计理念,显著降低了硬件适配的复杂性和成本。适配代码量减少80%,这使得硬件厂商能够更快地将其产品与飞桨框架集成,提升了市场竞争力。
插件式架构的灵活性
插件式架构允许硬件厂商根据自身需求灵活实现功能分离,简化了接入流程。这种“即插即用”的模式不仅提高了开发效率,还降低了与飞桨协同开发的成本,适合多种硬件环境的快速适配。
性能提升的实际案例
以燧原GCU为例,采用飞桨的图优化方案后,推理速度提升了2.2倍。这一成果表明,针对特定应用场景的优化能够显著提高模型的执行效率,值得其他硬件厂商借鉴。
延伸问答
飞桨框架3.0版本的主要创新是什么?
飞桨框架3.0版本推出了多硬件统一适配方案,采用“分层解耦、多元接入”的设计理念。
插件式硬件图接入方案如何提升模型推理性能?
通过图优化方案,燧原GCU使推理速度提升2.2倍,减少CPU调度开销。
飞桨框架如何降低硬件适配成本?
通过硬件接口抽象,适配代码量减少80%,降低了硬件适配成本。
飞桨框架提供了哪些硬件接入方式?
飞桨提供算子开发、算子映射、图接入、编译器接入等多种接入方式。
子图机制在飞桨框架中有什么作用?
子图机制将多个OP融合为一个OP,减少CPU启动硬件kernel的次数,提高执行效率。
未来飞桨框架的优化方向是什么?
未来将扩展子图支持更多OP,优化硬件kernel融合能力,提高内存复用率。
