

💡
原文中文,约1700字,阅读约需5分钟。
📝
内容提要
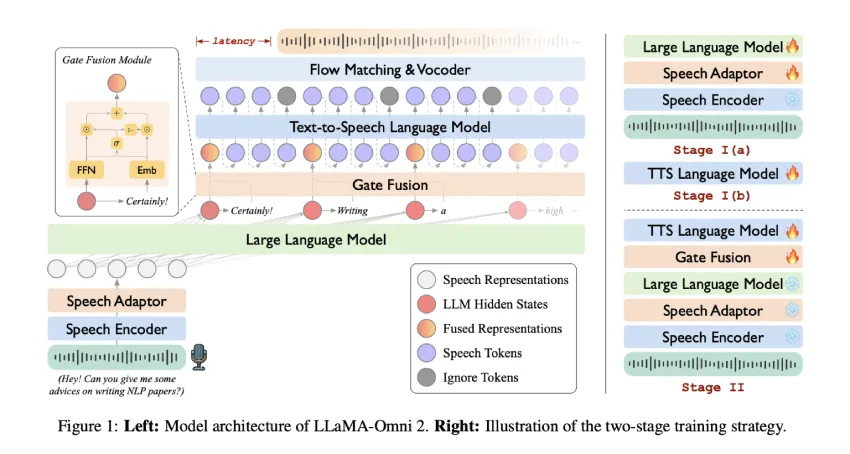
中国科学院计算技术研究所推出的LLaMA-Omni2是一个支持语音的大型语言模型,结合语音感知与语言理解,实现实时口语对话。该模型采用端到端流水线,训练成本低且具有模块化可解释性。在200K语音对话样本上训练后,LLaMA-Omni2的表现优于基线模型,证明高质量、低延迟的语音交互无需大量语料库。
🎯
关键要点
- LLaMA-Omni2是中国科学院计算技术研究所推出的支持语音的大型语言模型。
- 该模型结合语音感知与语言理解,实现实时口语对话。
- LLaMA-Omni2采用端到端流水线,具有模块化可解释性和低训练成本。
- 模型参数范围从0.5亿到140亿,基于Qwen2.5-Instruct系列构建。
- 模型包括语音编码器、语音适配器、核心LLM和流式TTS解码器。
- 流式生成采用读写策略,最大限度减少延迟并实现文本与语音的同步生成。
- LLaMA-Omni2在200K语音对话样本上训练,性能优于基线模型。
- 训练分为两个阶段:独立优化语音转文本和文本转语音模块,随后微调语音到语音生成路径。
- 门控融合模块在对齐文本和上下文信号中起重要作用。
- 研究表明,多轮对话数据在训练语音交互能力方面更有效。
- LLaMA-Omni2证明了无需大量语音语料库即可实现高质量、低延迟的语音交互。
➡️
