
SmoothConv & DuplexConv:面向对话式 AI的大规模中文全双工语音数据集开源!
内容提要
全双工人机交互技术受到关注,ASLP实验室与上海元音矩阵科技公司联合开源了SmoothConv和DuplexConv两个中文长音频对话数据集。这些数据集包含真实对话场景,旨在支持语音大模型研发,提供高质量对话数据,涵盖教育和闲聊领域,助力全双工系统的中断与响应决策。
关键要点
-
全双工人机交互技术成为学术界与工业界的关注焦点。
-
ASLP实验室与上海元音矩阵科技公司联合开源SmoothConv与DuplexConv两个中文长音频对话数据集。
-
数据集包含真实的中文自然对话场景,覆盖教育与闲聊领域,旨在支持语音大模型研发。
-
SmoothConv数据集包含100小时高密度专家级人工精标数据,适用于交互基准与算法微调。
-
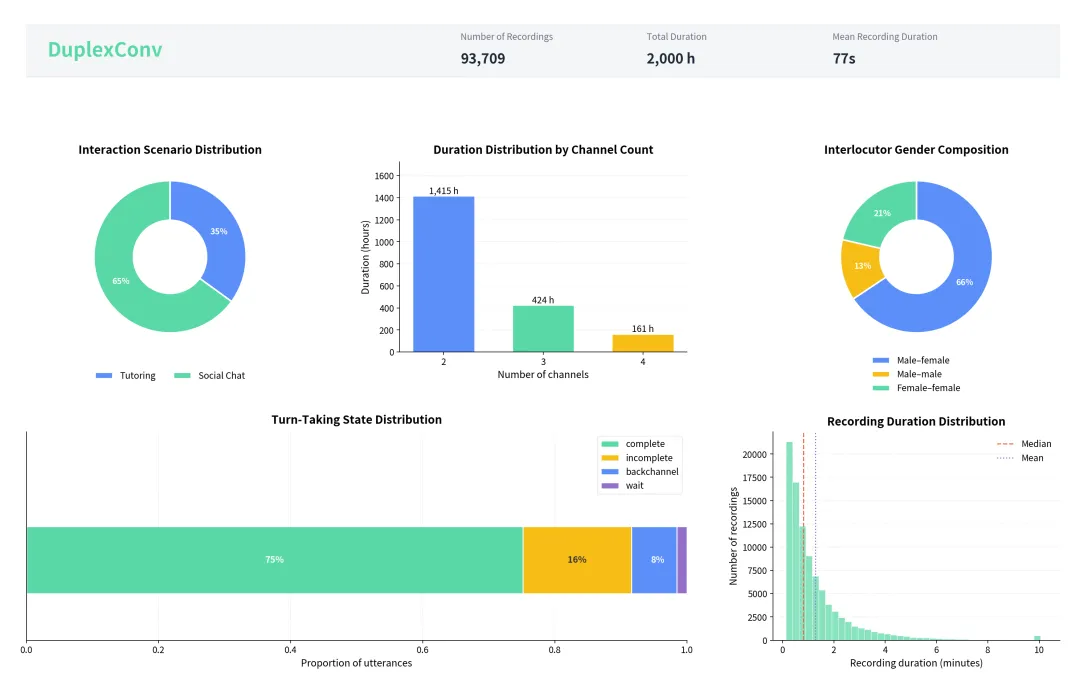
DuplexConv数据集提供2000小时大规模自动化标注数据,满足大规模语音预训练模型的需求。
-
数据集提供精准的话轮转换、停顿、多维副语言及声音事件标签,助力全双工系统的中断与响应决策。
-
SmoothConv与DuplexConv的开源旨在解决全双工系统研发的核心挑战,提升交互的流畅性与准确性。
延伸解读
全双工交互的技术挑战
全双工人机交互技术的实现面临多重挑战,包括如何在复杂环境中进行有效的声音过滤和决策。SmoothConv与DuplexConv数据集通过提供丰富的停顿和话轮转换标签,帮助模型训练出更精准的端点检测能力,从而降低交互延迟,提升用户体验。
数据集的多样性与应用
SmoothConv与DuplexConv数据集不仅涵盖教育和闲聊领域,还提供多维副语言标签,适用于多种任务,如情感计算和多说话人语音识别。这种多样性使得研究人员能够在不同场景下进行模型训练,推动全双工系统的广泛应用。
开源的意义与前景
SmoothConv与DuplexConv的开源为语音技术研究提供了宝贵资源,促进了学术界与工业界的合作。通过共享数据集,研究人员可以共同探索全双工交互的潜力,推动技术的进步与应用落地,形成良性循环。
延伸问答
SmoothConv和DuplexConv数据集的主要用途是什么?
这两个数据集旨在支持语音大模型研发,提供高质量的对话数据,特别是用于全双工人机交互系统的中断与响应决策。
SmoothConv和DuplexConv数据集的标注特点是什么?
SmoothConv包含100小时高密度专家级人工精标数据,DuplexConv提供2000小时大规模自动化标注数据,均涵盖话轮转换、停顿及副语言标签等。
这两个数据集如何帮助提升全双工系统的性能?
通过提供丰富的真实对话场景和精准的标签,帮助模型更好地理解人类交互,降低交互延迟,提高响应的流畅性与准确性。
SmoothConv数据集的核心标注维度有哪些?
核心标注维度包括音字精准对齐、节奏与非言语事件、话轮动态标签及细粒度属性,如说话人性别和情感状态。
DuplexConv数据集的规模和特点是什么?
DuplexConv提供2000小时的大规模自动化标注数据,旨在满足大规模语音预训练模型的需求,具有高度多样性。
SmoothConv和DuplexConv数据集的开源目的是什么?
开源旨在解决全双工系统研发的核心挑战,促进语音科研人员和工业界的合作与技术进步。
