
通义3D-Speaker多说话人日志功能
内容提要
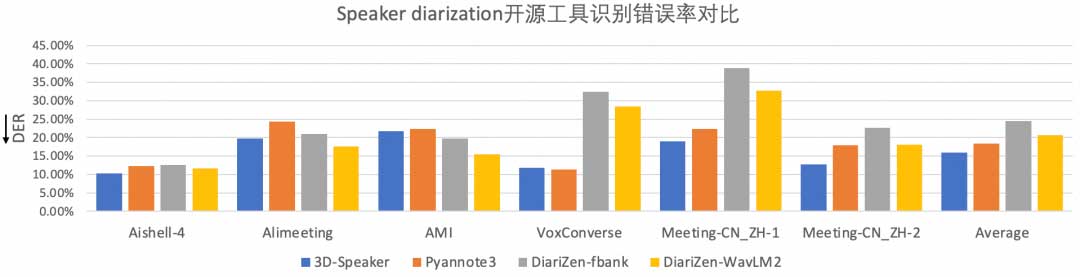
说话人日志任务旨在识别音频中的不同说话人及其发言时间。3D-Speaker工具通过特征提取与EEND网络的结合,提升了重叠语音的识别能力,并在多个基准测试中表现优异,推理速度快,适合大规模对话数据处理。
关键要点
-
说话人日志任务旨在识别音频中的不同说话人及其发言时间。
-
3D-Speaker工具通过特征提取与EEND网络的结合,提升了重叠语音的识别能力。
-
3D-Speaker在多个基准测试中表现优异,推理速度快,适合大规模对话数据处理。
-
传统方法基于特征提取和无监督聚类,无法识别重叠语音说话人。
-
EEND网络能够直接输出每个说话人的语音活动检测结果,适合重叠区域识别。
-
3D-Speaker框架结合了特征提取和EEND,分别负责全局人数和局部重叠说话人的检测。
-
采用小参数量模型,推理速度在CPU设备上达到RTF 0.03,效率明显优于其他工具。
-
提供了相关文献参考,支持进一步研究。
延伸解读
说话人日志的应用场景
说话人日志技术在会议记录、电话客服和多方视频通话等场景中具有广泛应用。通过准确识别不同说话人的发言时间,可以提高信息整理的效率,帮助用户更好地理解对话内容。
EEND网络的优势与局限
EEND网络在处理重叠语音方面表现出色,但其依赖于大量标注数据,这在实际应用中可能成为瓶颈。此外,人数估计和长时音频处理的挑战也限制了其单独使用的效果。
3D-Speaker的技术创新
3D-Speaker通过结合特征提取与EEND网络,提升了说话人日志的识别能力。这种创新使得系统在处理复杂对话时,能够同时兼顾全局和局部信息,显著提高了识别的准确性和效率。
延伸问答
什么是说话人日志任务?
说话人日志任务是将音频划分为不同说话人的多个段落,识别每个说话人的发言时间。
3D-Speaker工具如何提升重叠语音的识别能力?
3D-Speaker通过特征提取与EEND网络的结合,提升了重叠语音的识别能力。
3D-Speaker在基准测试中的表现如何?
3D-Speaker在多个基准测试中表现优异,推理速度快,适合大规模对话数据处理。
传统的说话人日志方法有哪些局限性?
传统方法无法识别重叠语音说话人,主要依赖特征提取和无监督聚类。
EEND网络在说话人日志中有什么优势?
EEND网络能够直接输出每个说话人的语音活动检测结果,适合识别重叠区域。
3D-Speaker的推理速度如何?
3D-Speaker在CPU设备上的推理速度达到RTF 0.03,效率明显优于其他工具。
