
Agent设计模式——第 9 章:学习和适应
内容提要
学习和适应是提升人工智能代理能力的关键。通过强化学习、监督学习和无监督学习,代理能够自主改进和优化性能。自我改进编码代理(SICA)展示了代理如何通过修改自身代码来增强能力。Google的AlphaEvolve结合大语言模型和进化算法,发现新算法,推动科学研究和计算技术的发展。
关键要点
-
学习和适应是增强人工智能代理能力的关键。
-
代理通过经验和环境交互实现自主改进,超越预定义参数。
-
强化学习、监督学习和无监督学习是代理学习的主要方法。
-
自我改进编码代理(SICA)通过修改自身代码来增强能力。
-
Google的AlphaEvolve结合大语言模型和进化算法,发现新算法。
-
SICA通过迭代循环改进其代码库,提升在编码挑战中的性能。
-
AlphaEvolve在基础研究和实际计算应用中展示了显著改进。
-
自适应代理能够在动态环境中表现出增强的性能。
-
DPO方法简化了大语言模型与人类偏好的对齐过程。
-
学习和适应模式对于需要个性化和持续性能改进的应用至关重要。
延伸解读
学习与适应的重要性
学习和适应是人工智能代理在动态环境中表现出色的关键。通过不断与环境互动,代理能够优化其决策过程,提升应对新情况的能力。这种能力使得代理在复杂的现实场景中能够实现更高的自主性,避免了传统静态系统的局限性。
自我改进编码代理(SICA)的创新
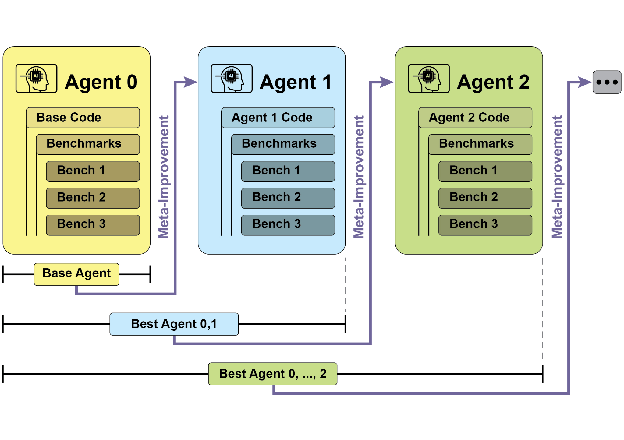
SICA通过自我修改代码来提升性能,展示了人工智能代理的自我进化潜力。与传统的训练方法不同,SICA能够直接从过去的表现中学习并进行迭代改进,这种机制为未来的智能系统设计提供了新的思路和方向。
AlphaEvolve的应用前景
Google的AlphaEvolve结合了大语言模型和进化算法,展现了在基础研究和实际计算中的巨大潜力。它不仅能优化算法,还能推动科学研究的进展,预示着未来人工智能在算法发现和优化领域的广泛应用。
延伸问答
学习和适应在人工智能代理中有什么重要性?
学习和适应使人工智能代理能够超越预定义参数,通过经验和环境交互实现自主改进,从而优化性能。
自我改进编码代理(SICA)是如何工作的?
SICA通过审查过去版本的性能,选择最佳版本并修改其代码库,以提升在编码挑战中的表现。
Google的AlphaEvolve有什么创新之处?
AlphaEvolve结合大语言模型和进化算法,能够自主发现和优化算法,推动科学研究和计算技术的发展。
强化学习、监督学习和无监督学习的区别是什么?
强化学习通过奖励和惩罚学习最优行为,监督学习从标注示例中学习映射关系,无监督学习则在未标注数据中发现模式。
DPO方法与传统的PPO方法有什么不同?
DPO方法直接使用人类偏好数据更新模型策略,而PPO方法需要先训练奖励模型再进行微调,DPO更简单直接。
自适应代理在实际应用中有哪些用例?
自适应代理可用于个性化助手、交易机器人、应用程序优化、欺诈检测等多个领域,提升性能和用户体验。
