
开放平台,统一管道:为何在Databricks上使用dbt能够加速数据转型
内容提要
dbt在Databricks平台上运行,整合数据转型工作流,提供开放存储和统一治理。通过Unity Catalog,团队高效管理数据权限和访问,简化操作复杂性。Databricks的高性能引擎提升ETL工作负载效率,减少手动调优需求,帮助用户专注于构建数据管道。
关键要点
-
dbt为数据转型工作流提供结构,帮助团队将原始数据转化为可供下游使用的精细数据集。
-
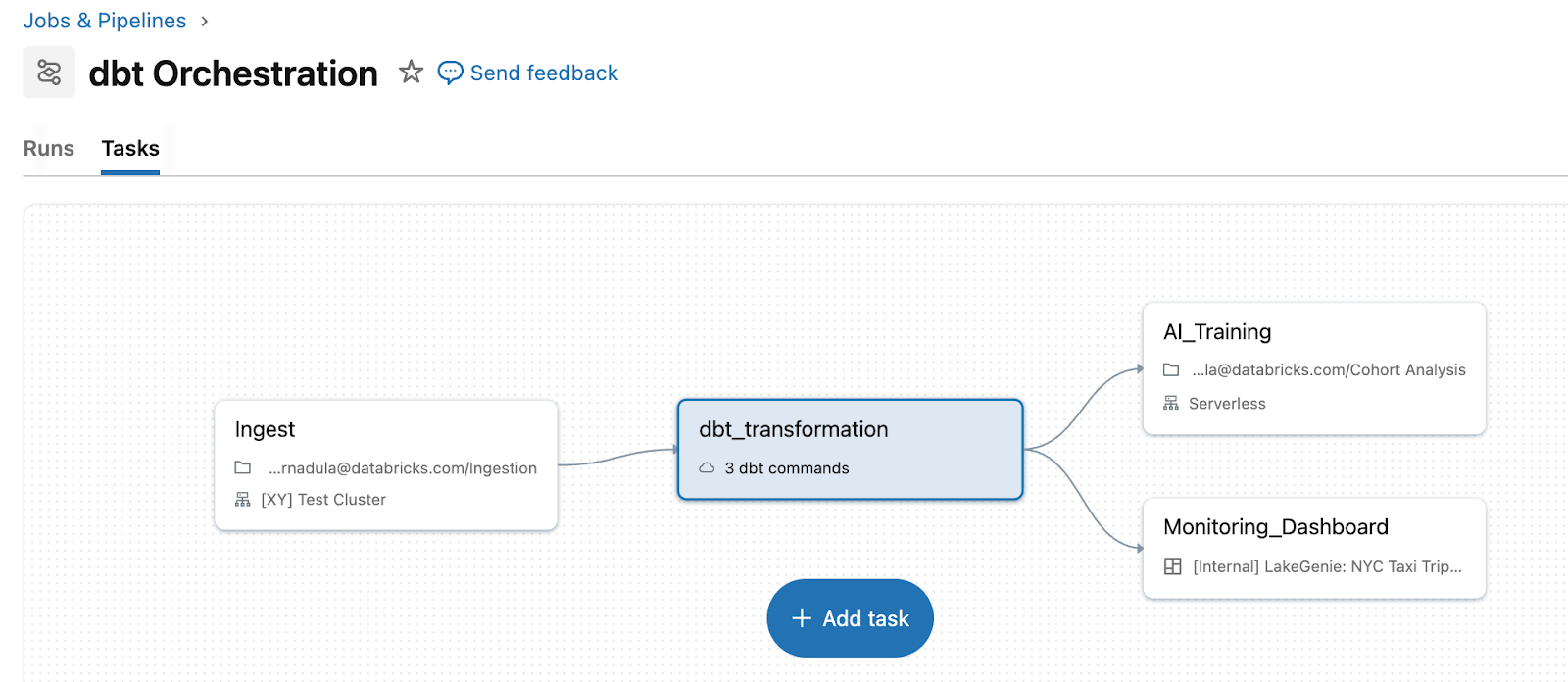
在Databricks上运行dbt,可以将多个数据源和笔记本整合到一个统一的治理数据平台中。
-
Unity Catalog使得团队能够高效管理数据权限和共享,简化了操作复杂性。
-
Databricks是一个开放的湖仓平台,确保数据存储和治理不依赖于单一查询引擎。
-
通过Lakeflow Jobs,dbt可以作为统一管道中的一类任务,简化了操作和调试过程。
-
Unity Catalog统一了访问控制、发现和数据血缘,提供了清晰的表内容、所有权和访问权限信息。
-
通过查询标签,团队可以追踪dbt运行的成本,提供真实的支出数据。
-
Databricks结合高性能执行引擎和原生支持的功能,提升了ETL工作负载的效率,减少了手动调优的需求。
延伸解读
数据治理的重要性
在数据转型过程中,数据治理是确保数据质量和安全的关键。Databricks的Unity Catalog提供了统一的访问控制和数据血缘追踪,帮助团队清晰了解数据的来源和使用情况。这种透明度不仅提升了数据的可信度,也减少了因权限管理不当而导致的数据泄露风险。
开放平台的优势
Databricks作为一个开放湖仓平台,允许用户在不同的查询引擎上访问和使用数据。这种开放性避免了数据锁定的风险,使得团队能够灵活地选择最适合的工具和技术,提升了数据转型的效率和灵活性。
简化操作的潜力
通过将dbt与Lakeflow Jobs结合,Databricks简化了数据管道的操作流程。团队可以在一个统一的工作流中处理数据的提取、转化和加载,减少了系统间的切换和调试复杂性。这种一体化的方式有助于提高团队的工作效率,降低了操作错误的可能性。
