
开源大语言模型背后的架构
💡
原文英文,约1800词,阅读约需7分钟。
📝
内容提要
npx workos推出了一款AI代理,能够将身份验证直接集成到现有代码中。DeepSeek V3及其他模型采用混合专家架构,优化了计算效率和内存使用,推动了开源生态的发展。
🎯
关键要点
-
npx workos推出了一款AI代理,能够将身份验证直接集成到现有代码中。
-
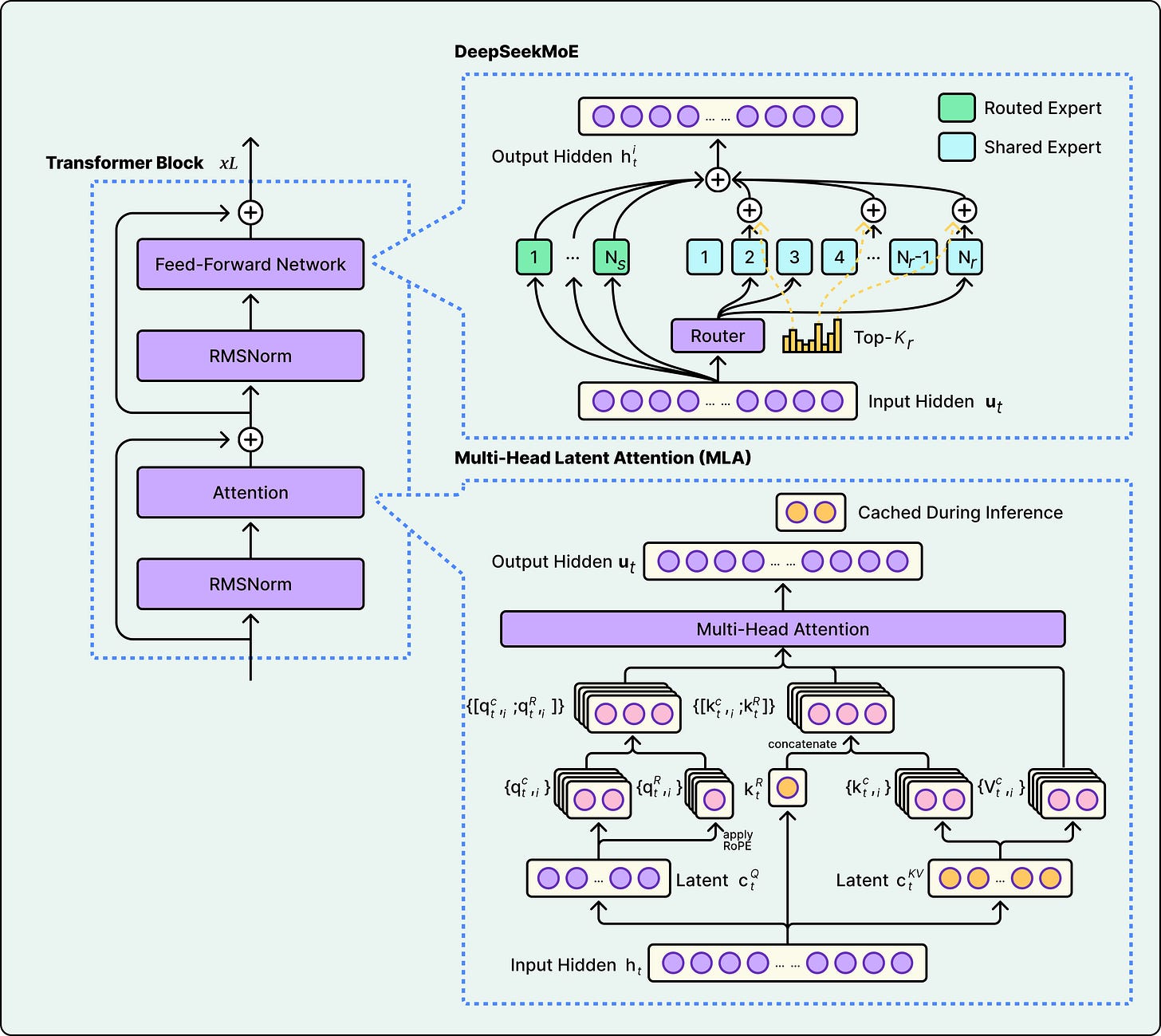
DeepSeek V3采用混合专家架构,优化了计算效率和内存使用。
-
DeepSeek V3的训练成本为557.6万美元,使用了多头潜在注意力机制。
-
混合专家架构通过多个小型专家网络和学习路由器来提高模型效率。
-
每个模型的总参数和活跃参数是评估模型性能的重要指标。
-
几乎所有标榜为“开源”的模型实际上是开放权重,训练数据和完整训练代码通常不可见。
-
不同模型在处理长上下文时采用不同的注意力策略,如分组查询注意力和稀疏注意力。
-
模型的稀疏性设计在训练和验证损失方面存在分歧,增加专家数量可以改善性能,但也增加了基础设施复杂性。
-
训练方法的多样性是模型之间的主要区别,包括强化学习、蒸馏和合成数据。
-
架构趋同,大家都在构建混合专家变换器,但训练方法各有不同。
➡️
