
用 Strands Agents SDK 构建确定性数据分析:语义层 + VQR 在 Amazon Bedrock 上的实践
内容提要
本文介绍了一种基于Strands Agents SDK和Amazon Bedrock的确定性数据分析架构,旨在解决企业数据分析中自然语言生成SQL的挑战。该架构由语义层、VQR知识库和Agent层组成,确保高频查询的准确性和可复用性,降低LLM调用频率,从而优化成本和响应时间,强调在不需要时避免使用LLM,以提高效率和稳定性。
关键要点
-
企业数据分析中,LLM 直接生成 SQL 面临不可复现、不可审计、不可收敛三大挑战。
-
提出基于 Strands Agents SDK 和 Amazon Bedrock 的三层确定性架构:语义层、VQR 知识库和 Agent 层。
-
语义层将业务术语映射为标准 SQL 片段,确保高频查询的准确性和可复用性。
-
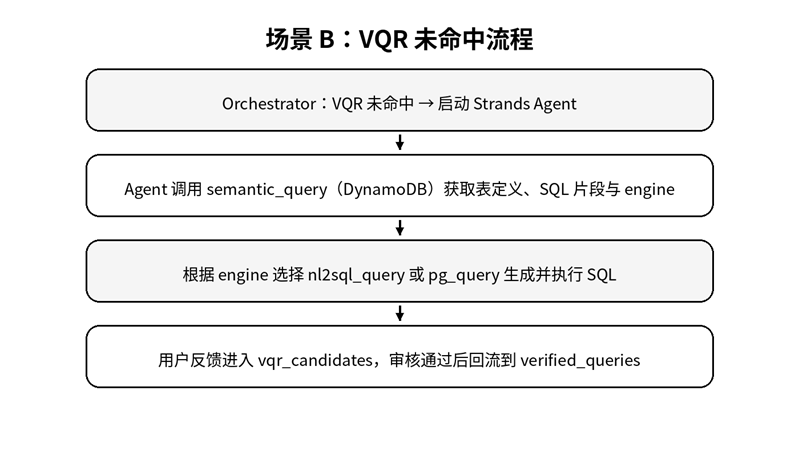
VQR 知识库通过反馈机制缓存验证查询,降低 LLM 调用频率,优化成本和响应时间。
-
强调在不需要时避免使用 LLM,以提高效率和稳定性。
-
系统运行越久,VQR 命中率越高,LLM 调用越少,成本与时延会形成持续优化飞轮。
-
三层架构设计的核心原则是:能不用 LLM 就不用,必须用 LLM 时尽量少用。
-
VQR 机制引入了知识积累维度,允许高频问题的查询成本逐渐降低。
-
VQR 适合处理已知且重复的问题,但不具备真正的语义理解与推理能力。
-
未来的演进方向是将 VQR 作为 LLM 的高质量参考输入,提升语义理解能力和回答效果。
延伸解读
确定性数据分析的优势
通过引入 Strands Agents SDK 和 VQR 知识库,企业能够实现更高效的自然语言数据查询。该架构不仅提高了查询的准确性和可复用性,还显著降低了对大语言模型(LLM)的依赖,从而减少了成本和响应时间。这种确定性分析方法为企业提供了更可靠的数据决策支持,尤其在高频查询场景中表现突出。
VQR 的局限性与适用场景
尽管 VQR 在处理高频、重复性查询时表现优异,但它并不具备真正的语义理解能力。对于查询意图复杂或变化较大的问题,VQR 可能无法提供准确的 SQL 映射。因此,企业在使用 VQR 时需明确其适用场景,确保其在稳定的查询逻辑下发挥最大效用。
架构设计的灵活性
Strands Agents SDK 的架构设计强调灵活性与可扩展性,能够适应不同的数据源和业务需求。随着企业数据量的增加,系统可以通过动态加载语义层和 VQR 知识库来优化查询效率。这种设计不仅降低了维护成本,还能快速响应业务变化,确保数据分析的持续有效性。
延伸问答
Strands Agents SDK 和 Amazon Bedrock 的结合有什么优势?
Strands Agents SDK 提供了代码优先的灵活性,适合深度定制的场景,而 Amazon Bedrock 提供了开箱即用的托管方案,两者结合可以在数据分析中实现高效的自然语言查询。
VQR 机制如何优化数据查询成本?
VQR 机制通过缓存已验证的查询,允许高频问题直接执行 SQL,避免了重复调用 LLM,从而降低了查询成本和响应时间。
三层确定性架构的核心原则是什么?
三层确定性架构的核心原则是:能不用 LLM 就不用,必须用 LLM 时尽量少用,以确保查询的准确性和效率。
语义层在数据分析中起什么作用?
语义层负责将业务术语映射为标准 SQL 片段,确保高频查询的准确性和可复用性,从而提高数据分析的可靠性。
企业在自然语言查询中面临哪些主要挑战?
企业在自然语言查询中面临的主要挑战包括 LLM 输出的概率性、缺乏业务语义理解和缺乏学习能力,导致查询结果不稳定。
VQR 机制的局限性是什么?
VQR 机制的局限性在于它不具备真正的语义理解与推理能力,无法处理字面相近但语义不同的问题。
