
大型语言模型如何学习
内容提要
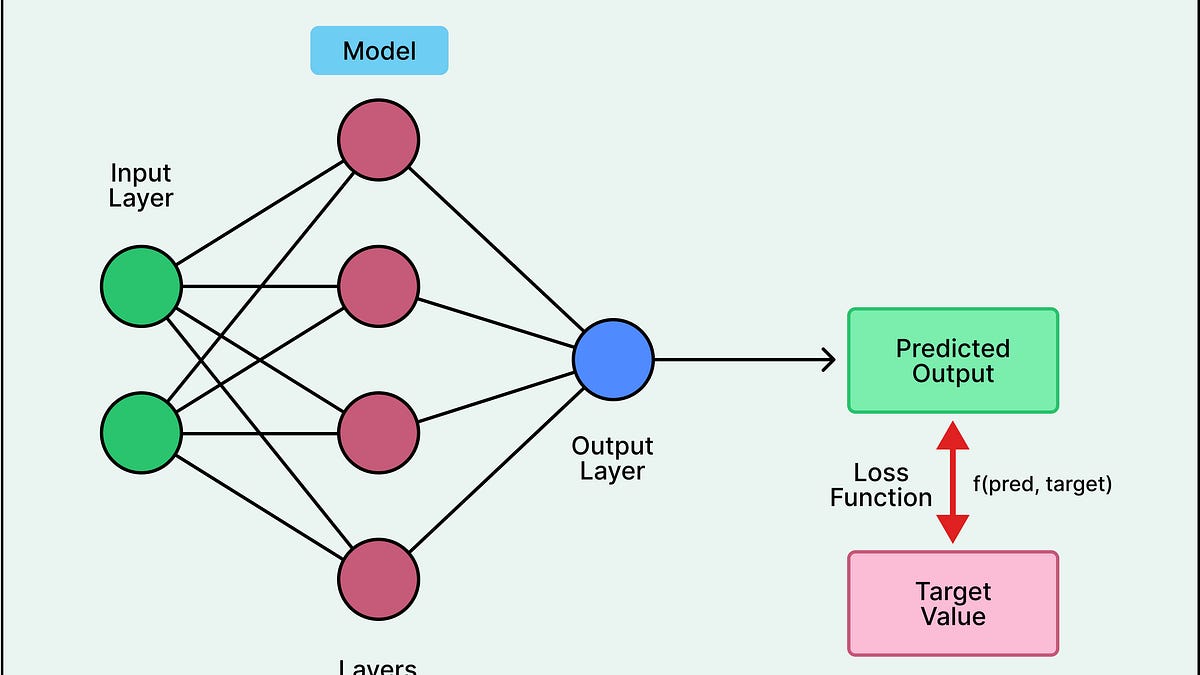
要有效监控大型语言模型(LLMs),需了解其工作原理。LLMs通过调整参数模仿文本模式,而非真正理解。训练中使用损失函数评估性能,梯度下降算法优化模型。尽管LLMs能生成流畅文本,但缺乏推理能力,容易在新问题上出错,因此使用时需谨慎,验证输出的准确性。
关键要点
-
有效监控大型语言模型(LLMs)需要了解其工作原理。
-
LLMs通过调整参数模仿文本模式,而非真正理解。
-
损失函数用于评估模型性能,目标是将其值尽可能降低。
-
良好的损失函数需具体、可计算且平滑。
-
LLMs的评分基于匹配训练数据中的模式,而非真实或正确性。
-
梯度下降算法用于调整模型参数以减少损失。
-
现代LLMs使用随机梯度下降(SGD)来处理大规模数据集。
-
LLMs的训练任务是预测序列中的下一个单词。
-
上下文信息有助于提高LLMs的预测准确性。
-
LLMs在模式匹配方面表现出色,但缺乏推理能力。
-
当面临新问题或准确性至关重要时,使用LLMs需谨慎。
-
始终验证重要用例的输出,不能仅凭自信的回答判断正确性。
-
LLMs是识别和再现文本模式的工具,理解其局限性有助于更有效地使用它们。
延伸解读
理解损失函数的重要性
损失函数是评估大型语言模型(LLMs)性能的关键工具。它不仅需要具体、可计算,还要平滑,以便训练算法能够有效调整模型参数。了解损失函数的设计原则,可以帮助开发者更好地优化模型,避免因错误的评估标准导致的性能下降。
梯度下降的局限性
梯度下降算法虽然在调整模型参数时非常有效,但其局限性在于只能考虑当前状态的最优解,而无法预见更好的解决方案。这种局限性可能导致模型在复杂问题上陷入局部最优解,影响其在新问题上的表现。
模式匹配与推理能力的区别
LLMs擅长模式匹配,但缺乏真正的推理能力。这意味着在面对新问题或不熟悉的领域时,模型可能会产生错误的答案。用户在使用LLMs时应保持谨慎,尤其是在需要准确性和逻辑推理的场景中,始终验证输出的正确性。
延伸问答
大型语言模型是如何进行学习的?
大型语言模型通过调整内部参数来模仿文本模式,而不是通过理解和推理来学习。
损失函数在大型语言模型训练中有什么作用?
损失函数用于评估模型性能,目标是将其值尽可能降低,以便更好地调整模型参数。
梯度下降算法是如何优化大型语言模型的?
梯度下降算法通过计算损失函数的斜率,逐步调整模型参数,以减少损失并提高性能。
大型语言模型在处理新问题时存在哪些局限性?
大型语言模型缺乏推理能力,容易在新问题上出错,且可能生成不准确的答案。
上下文信息如何影响大型语言模型的预测准确性?
上下文信息可以帮助模型更好地缩小预测范围,从而提高预测的准确性。
使用大型语言模型时需要注意什么?
使用大型语言模型时应谨慎,特别是在处理新问题或准确性至关重要的情况下,始终验证输出的准确性。
