
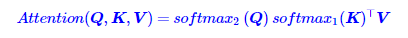
transformer and attention(三)
原文中文,约30900字,阅读约需74分钟。
📝
内容提要
本文介绍了视觉领域中使用transformer的方法,包括Vision Transformer、SASA-Layer和Rethinking and Improving Relative Position Encoding for Vision Transformer等模型。这些方法在图像分类和其他视觉任务中表现出色。
🎯
关键要点
-
本文介绍了视觉领域中使用transformer的方法,包括Vision Transformer、SASA-Layer和Rethinking and Improving Relative Position Encoding for Vision Transformer等模型。
-
线性注意力通过去掉Softmax操作降低了复杂度,探索了注意力机制的分布特性。
-
图像中的transformer与注意力机制结合,采用相对位置编码处理二维数据。
-
Vision Transformer通过patch embedding和位置编码处理图像数据,表现出色。
-
卷积注意力结合了绝对位置和相对位置编码,利用2D卷积处理图像数据。
-
SASA-Layer改进了相对位置编码的方法,提出了偏向模式和语境模式。
-
Rethinking and Improving Relative Position Encoding for Vision Transformer研究了相对位置编码的独立性。
-
Swin Transformer通过分层结构和移位窗口方案提高了计算效率,适应视觉任务的需求。
-
Twins架构重新审视了空间注意力的设计,提出了高效的视觉转换器结构。
🏷️
