
在生成式AI中大规模跟踪和控制数据流:Meta的隐私感知基础设施
内容提要
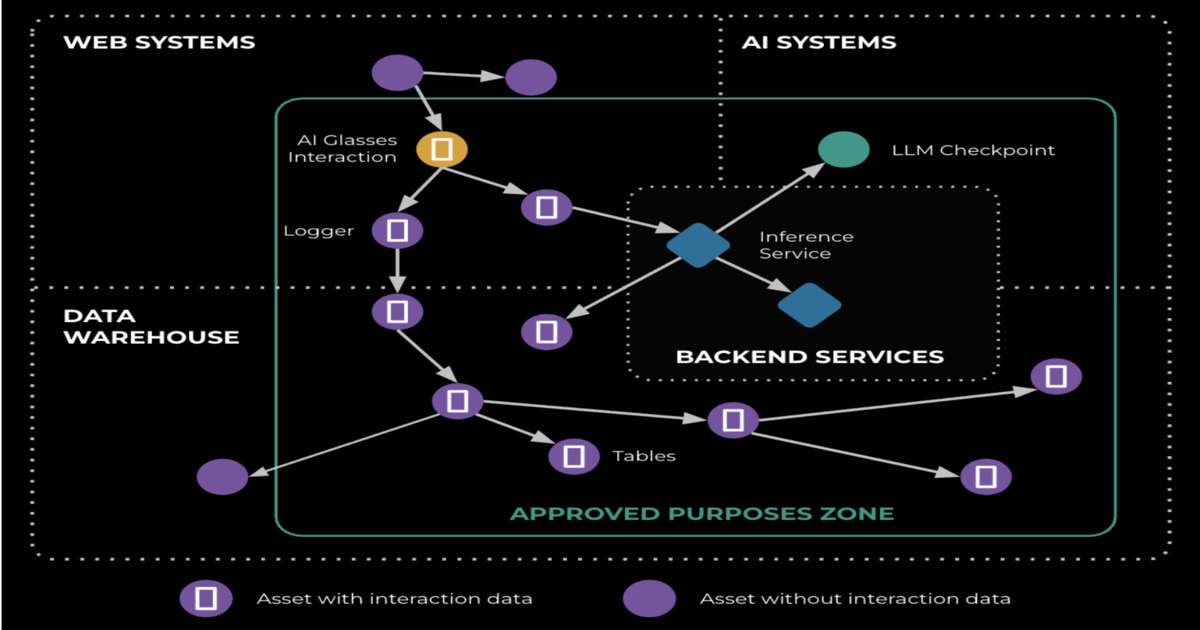
Meta发布了隐私基础设施的新细节,以支持生成式AI产品的开发。工程师们指出,生成式AI带来了新的隐私挑战,因此扩展了隐私感知基础设施(PAI),将隐私控制嵌入数据存储和处理流程中。通过大规模数据血缘追踪,Meta能够持续评估隐私政策,并在数据流动中实施政策控制,以确保隐私合规。
关键要点
-
Meta发布了隐私基础设施的新细节,以支持生成式AI产品的开发。
-
生成式AI工作负载带来了新的隐私挑战,包括数据量增加和数据处理速度加快。
-
隐私感知基础设施(PAI)被扩展,以将隐私控制嵌入数据存储和处理流程中。
-
大规模数据血缘追踪提供了数据来源和传播的可见性,支持隐私政策的持续评估。
-
共享隐私库PrivacyLib被嵌入基础设施层,以标准化隐私元数据的捕获。
-
政策控制被添加以管理数据的存储、访问和使用,实时评估数据流。
-
隐私工作流程分为四个阶段:理解数据、发现数据流、执行政策和证明合规。
-
Meta工程师表示,扩展生成式AI的隐私是一个持续的努力,PAI将继续发展以满足需求。
延伸解读
隐私基础设施的重要性
Meta的隐私感知基础设施(PAI)是应对生成式AI带来的隐私挑战的关键。随着数据量和处理速度的增加,传统的隐私管理方法已无法满足需求。PAI的扩展确保了隐私控制能够嵌入数据存储和处理流程中,从而提高了隐私合规性。
数据血缘追踪的优势
大规模数据血缘追踪为Meta提供了对数据来源和传播的清晰视图。这种可见性使得隐私政策能够在数据流动过程中持续评估和调整,确保在复杂的服务和产品之间,隐私控制能够一致地实施。
政策控制的实时评估
Meta在隐私基础设施中引入了基于政策的控制,能够实时评估数据流动。这意味着在数据使用过程中,系统能够即时检测并响应隐私违规行为,从而有效保护用户隐私。
持续的隐私管理挑战
Meta工程师指出,随着生成式AI技术的不断进步,隐私管理将面临新的挑战。PAI的持续演进和增强的数据血缘分析工具将是应对这些挑战的关键,确保隐私合规性不被忽视。
延伸问答
Meta的隐私基础设施是如何支持生成式AI产品开发的?
Meta的隐私基础设施通过扩展隐私感知基础设施(PAI),将隐私控制嵌入数据存储和处理流程中,以支持生成式AI产品的开发。
生成式AI带来了哪些隐私挑战?
生成式AI带来了数据量增加、新的数据形式和更快的迭代周期等隐私挑战。
Meta是如何进行数据血缘追踪的?
Meta通过大规模数据血缘追踪,提供数据来源和传播的可见性,以支持隐私政策的持续评估。
隐私库PrivacyLib的作用是什么?
PrivacyLib被嵌入基础设施层,以标准化隐私元数据的捕获,支持一致的政策评估。
Meta的隐私工作流程分为哪几个阶段?
隐私工作流程分为理解数据、发现数据流、执行政策和证明合规四个阶段。
Meta如何实时评估数据流中的隐私政策?
Meta通过政策控制在数据流动中实时评估隐私政策,检测并响应违规行为。
