
Google AI 推出VISTA:一款用于文本转视频生成的测试时自我改进智能体
内容提要
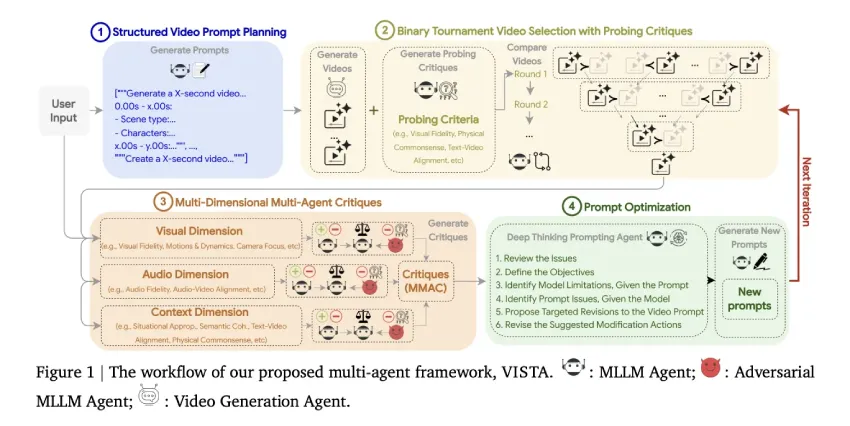
VISTA是一种多智能体框架,通过结构化提示和竞赛机制优化文本到视频生成,提升视觉、音频和上下文质量。研究表明,VISTA在多场景测试中表现优异,受到人类评审者的青睐。该系统分为四个步骤,实现显著改进和可重复收益。
关键要点
-
VISTA是一种多智能体框架,通过结构化提示和竞赛机制优化文本到视频生成。
-
VISTA在多场景测试中表现优异,受到人类评审者的青睐。
-
该系统分为四个步骤:结构化视频提示词规划、成对竞赛选择、多维度多智能体评价、深度思考提示智能体。
-
用户提示被分解为定时场景,每个场景包含9个属性。
-
候选视频通过成对比赛选出,评估标准包括视觉保真度、物理常识、文本视频对齐等。
-
多维度评审采用三位评审方式,评分范围为1到10分。
-
VISTA在第5次迭代中,单场景的胜率为45.9%,多场景的胜率为46.3%。
-
人类评估者在66.4%的试验中更喜欢VISTA的输出。
-
每次迭代的平均标记数约为70万,胜率随着迭代次数和标记数量的增加而增加。
-
VISTA的结构化提示规划和多维度评审方法有效减少了排序偏差,提升了生成质量。
延伸解读
VISTA的创新机制
VISTA通过结构化提示和成对竞赛机制,显著提升了文本到视频生成的质量。这种方法不仅优化了生成过程,还通过多维度评审减少了排序偏差,使得生成结果更符合用户期望。用户在使用时应关注提示的细节,以便更好地利用系统的优势。
人类评审的偏好
研究显示,66.4%的评审者更倾向于选择VISTA生成的输出,这表明该系统在实际应用中具有较高的用户满意度。用户在选择文本转视频工具时,可以考虑VISTA的表现,尤其是在需要高质量视觉和音频内容的场景中。
迭代与成本的关系
VISTA的胜率随着迭代次数和标记数量的增加而提升,表明持续优化是提高生成质量的关键。然而,每次迭代的平均标记数约为70万,这意味着在成本和资源投入上,用户需要做好充分的准备,以实现最佳效果。
延伸问答
VISTA是什么?
VISTA是视频迭代自我改进智能体的缩写,是一种多智能体框架,用于优化文本到视频生成。
VISTA的工作流程包括哪些步骤?
VISTA的工作流程包括四个步骤:结构化视频提示词规划、成对竞赛选择、多维度多智能体评价和深度思考提示智能体。
VISTA在测试中的表现如何?
在第5次迭代中,VISTA的单场景胜率为45.9%,多场景胜率为46.3%,并且66.4%的试验中人类评估者更喜欢其输出。
VISTA如何减少排序偏差?
VISTA通过成对淘汰赛选择和多维度评审来减少排序偏差,确保评估标准涵盖视觉保真度、物理常识等。
VISTA的评审标准是什么?
VISTA的评审标准包括视觉保真度、物理常识、文本视频对齐、音视频同步度和用户参与度等。
VISTA的迭代过程有什么特点?
VISTA的迭代过程每次平均标记数约为70万,胜率随着迭代次数和标记数量的增加而提高。
