LISA(推理分割)笔记
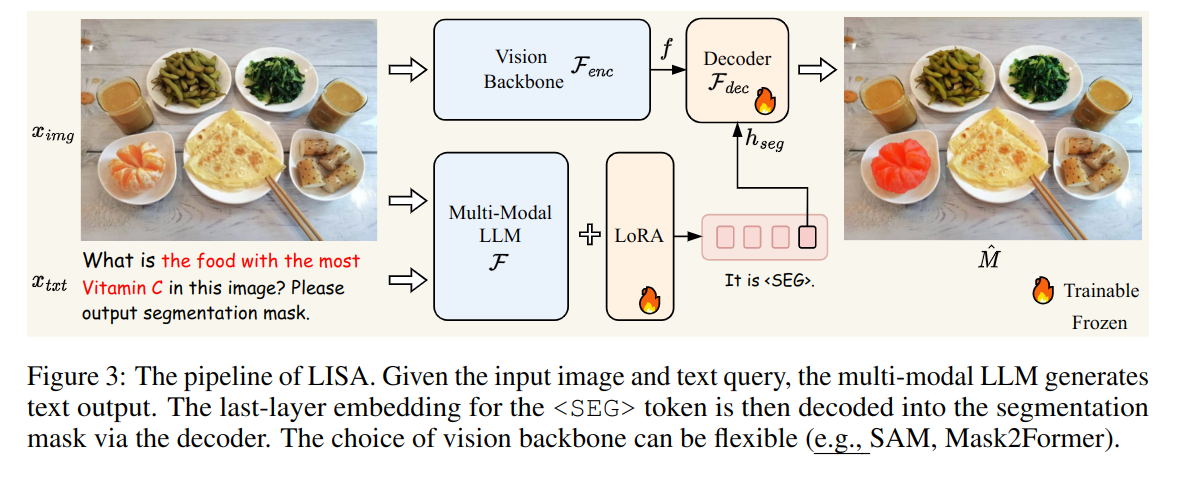
原文中文,约1700字,阅读约需4分钟。发表于:。LISA(推理分割)笔记 简介 这篇论文题目中文翻译是 基于大型语言模型的语义分割, 提出了一个新任务-推理分割。大概就是给一张图和一段话,模型使用大语言模型分割出目标。作者给了一个例子,从
本文介绍了推理分割任务及其基准模型,通过大语言模型分割图像和文本。模型包括生成mask和视觉编码器,训练目标为文本生成损失和分割掩码损失的加权和。训练数据包括语义分割、引用分割和视觉问答数据集。作者还提到LISA具有zero-shot能力,需要训练的参数包括解码器、llm的词嵌入和投影最后一层的mlp。