
TensorOpera AI 发布 Fox-1:系列小型语言模型包括 Fox-1-1.6B 和 Fox-1-1.6B-Instruct-v0.1
内容提要
TensorOpera AI 发布了 Fox-1 系列小型语言模型,旨在提供类似大型语言模型的功能,同时降低资源需求。该模型通过创新的训练策略和架构,提升了语言处理能力,并在多项基准测试中表现优异,适合硬件受限的应用。
关键要点
-
大型语言模型(LLM)因规模庞大和高资源需求而变得不实用。
-
TensorOpera AI 发布了 Fox-1 系列小型语言模型(SLM),旨在提供类似 LLM 的功能,同时降低资源需求。
-
Fox-1 包括两个主要变体:Fox-1-1.6B 和 Fox-1-1.6B-Instruct-v0.1,经过 3 万亿个网络抓取数据的预训练和 50 亿个标记的微调。
-
Fox-1 采用三阶段数据课程,确保训练从一般环境逐步过渡到高度专业化的环境。
-
Fox-1 的架构为更深层的仅解码器转换器,具有 32 层,使用分组查询注意(GQA)优化内存使用率。
-
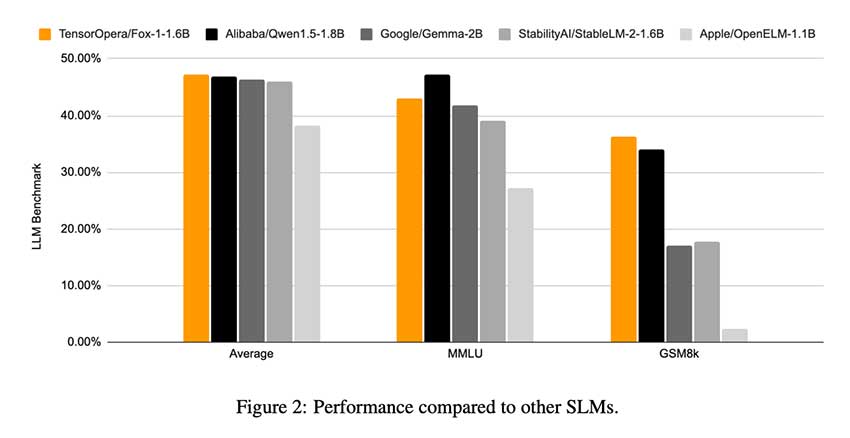
Fox-1 在多项基准测试中表现优异,特别是在 GSM8k 基准测试中实现了 36.39% 的准确率。
-
Fox-1 的推理效率高,每秒可实现超过 200 个 token,适合硬件受限的应用程序。
-
Fox-1 的发布标志着小型但功能强大的语言模型的开发向前迈出了重要一步,提供了可与大型模型相媲美的性能。
延伸解读
小型语言模型的优势
Fox-1 系列小型语言模型在资源需求上显著低于大型语言模型(LLM),使得更多研究人员和开发者能够使用先进的自然语言处理技术。这种可访问性有助于推动 AI 领域的创新,尤其是在资源有限的环境中。
技术创新与性能
Fox-1 采用了三阶段数据课程和分组查询注意(GQA)等技术创新,提升了模型的训练效率和推理速度。这些技术使得 Fox-1 在多项基准测试中表现优异,尤其是在 GSM8k 测试中,准确率达到 36.39%。
开源与社区影响
Fox-1 的开源发布标志着对强大语言模型的开放访问,促进了 AI 开发的民主化。这将使得更多的开发者能够在没有高昂成本的情况下,利用先进的语言处理能力,推动整个行业的发展。
延伸问答
Fox-1 系列语言模型的主要特点是什么?
Fox-1 系列语言模型具有高效的架构、先进的注意力机制和三阶段数据课程,旨在提供类似大型语言模型的功能,同时降低资源需求。
Fox-1 在基准测试中的表现如何?
Fox-1 在 GSM8k 基准测试中实现了 36.39% 的准确率,优于所有对比模型,包括更大的 Gemma-2B。
Fox-1 的推理效率如何?
Fox-1 每秒可实现超过 200 个 token 的推理效率,适合硬件受限的应用程序。
Fox-1 模型的训练数据来源是什么?
Fox-1 模型在 3 万亿个网络抓取数据上进行了预训练,并使用 50 亿个标记进行了微调。
Fox-1 系列模型的开源情况如何?
Fox-1 系列模型以 Apache 2.0 许可开源,旨在促进对强大语言模型的开放访问。
Fox-1 如何解决大型语言模型的可访问性问题?
Fox-1 提供高效且功能强大的模型,使得无法访问大型 LLM 所需计算基础设施的研究人员和开发者也能使用高级自然语言处理功能。
