

iGRPO:让 AI 像人类一样自我反思,数学推理能力再升级!
💡
原文中文,约1600字,阅读约需4分钟。
📝
内容提要
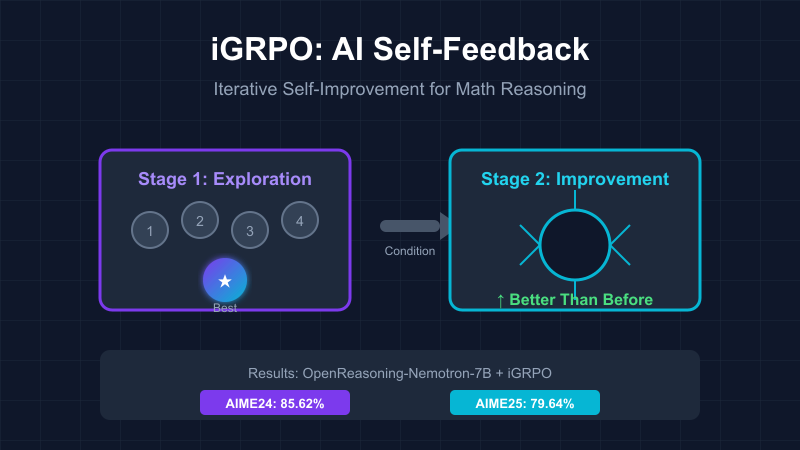
本文提出了iGRPO(迭代组相对策略优化),通过自我反馈提升AI的数学推理能力。该方法包括探索与选择、条件化改进两个阶段,显著提升多个基准测试的表现,且无需复杂的外部反馈。iGRPO的理念与人类学习相似,强调超越自我,具有广泛应用潜力。
🎯
关键要点
- 本文提出了iGRPO(迭代组相对策略优化),旨在提升AI的数学推理能力。
- 现有的强化学习方法依赖外部奖励信号,限制了AI的自我检查能力。
- iGRPO通过自我反馈机制,分为探索与选择、条件化改进两个阶段。
- 第一阶段,模型生成多个候选解决方案并选择最佳方案。
- 第二阶段,模型基于最佳方案进行进一步优化。
- iGRPO在多个基准测试中表现优异,显著提升了模型的推理能力。
- iGRPO有效延迟了强化学习中的熵崩溃问题,增强了模型的泛化能力。
- 使用生成式法官可以让模型理解评分原因,提升数学推理的可靠性。
- iGRPO的训练效率高,不需要复杂的外部批评模型,简化了训练流程。
- 该方法基于开源模型,具有可复现性,适合广泛应用。
- 论文来自NVIDIA Research,实验设计严谨,结果令人信服。
➡️
