
每天10万亿个样本:在Databricks超越传统监控基础设施的扩展
内容提要
Databricks推出了新的监控平台Pantheon,基于开源项目Thanos,能够实时处理50亿个活动时间序列,每天接收超过10万亿个样本。通过优化存储架构和聚合策略,Pantheon提高了监控系统的可靠性和效率,降低了云成本,减少了手动操作,并与Databricks的湖仓架构结合,提升了工程师的工作效率。
关键要点
-
Databricks推出了新的监控平台Pantheon,基于开源项目Thanos,能够实时处理50亿个活动时间序列,每天接收超过10万亿个样本。
-
Pantheon通过优化存储架构和聚合策略,提高了监控系统的可靠性和效率,降低了云成本,减少了手动操作。
-
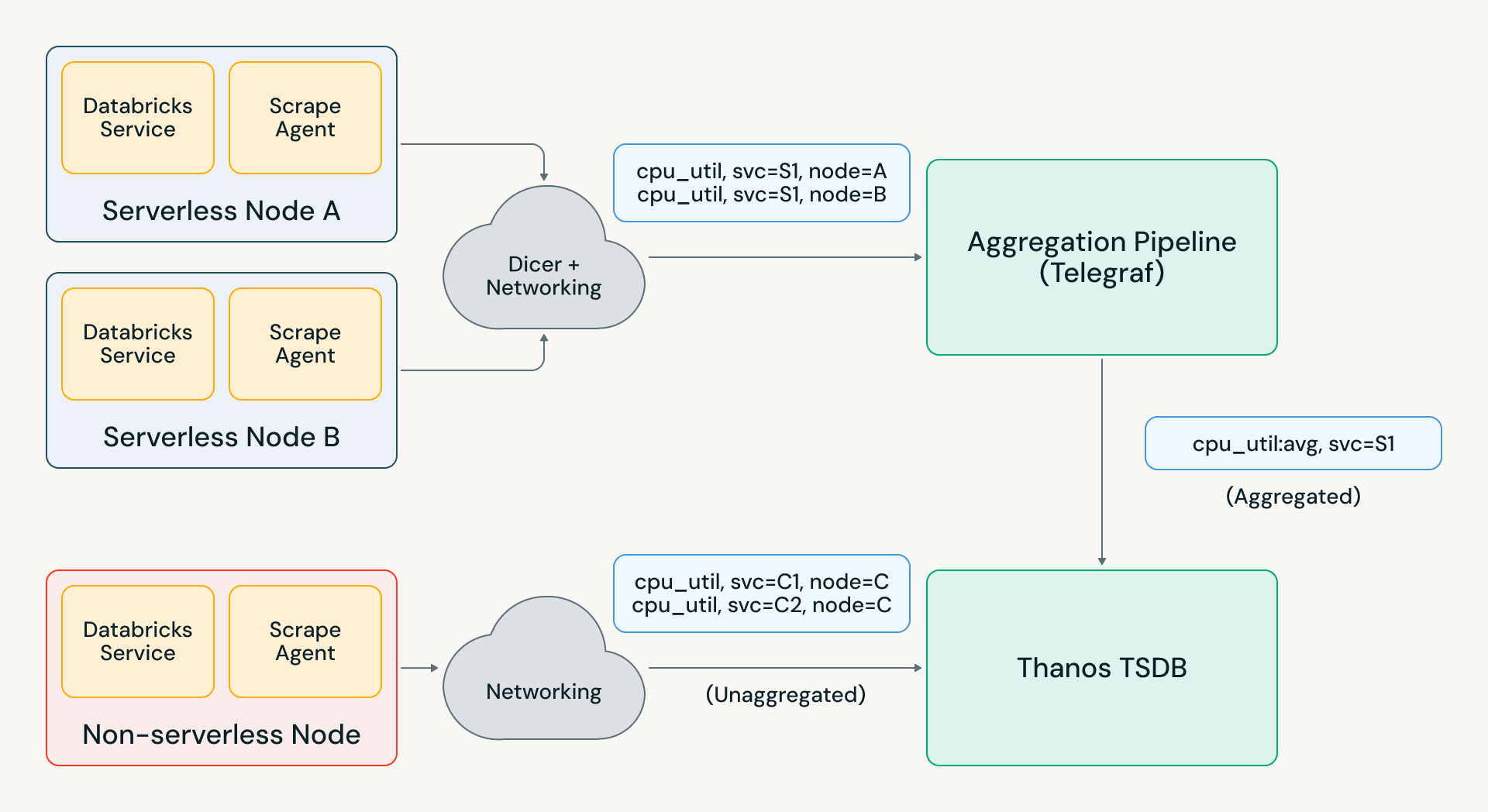
Pantheon的架构采用分层存储,最新的时间序列保存在内存中,过去24小时的数据保存在磁盘上,所有旧数据存储在对象存储中。
-
Pantheon引入了专门的控制平面,负责协调Thanos组件的生命周期和容量决策,以实现自动化和最小化人工干预。
-
为了应对快速增长的基数,Pantheon采用了聚合策略,去除高成本标签,同时提供服务所有者的聚合视图。
-
Hydra是一个新的原始故障排除数据平台,能够处理200亿个未聚合的活动时间序列,数据存储成本比Thanos低50倍。
-
Hydra与Grafana集成,支持PromQL查询,使工程师能够使用熟悉的界面进行高基数指标的调试。
-
Hydra的设计原则是统一指标语义,简化工程师的使用体验,减少认知负担。
延伸解读
Pantheon的架构优势
Pantheon采用分层存储架构,将最新的时间序列保存在内存中,过去24小时的数据保存在磁盘上,旧数据则存储在对象存储中。这种设计不仅提高了实时查询的性能,还有效降低了云存储成本,适应了Databricks快速增长的需求。
聚合策略的挑战与解决
随着监控基数的快速增长,Pantheon面临着高成本标签管理的挑战。通过实施聚合策略,Databricks能够在不牺牲服务所有者视图的情况下,减少高成本标签的存储,从而有效控制监控基础设施的扩展压力。
Hydra的创新设计
Hydra作为新的故障排除数据平台,能够处理高达200亿个未聚合的活动时间序列,其设计旨在简化工程师的使用体验。通过与Grafana的集成,Hydra使得工程师能够在熟悉的环境中进行高基数指标的调试,提升了工作效率。
延伸问答
Databricks的新监控平台Pantheon有什么特点?
Pantheon基于开源项目Thanos,能够实时处理50亿个活动时间序列,每天接收超过10万亿个样本,优化了存储架构和聚合策略,提高了监控系统的可靠性和效率。
Pantheon如何降低云成本和减少手动操作?
Pantheon通过优化存储架构和引入专门的控制平面,减少了监控基础设施的停机时间,并降低了人工干预的需求,从而节省了云成本。
Hydra平台与Pantheon有什么不同之处?
Hydra是一个新的故障排除数据平台,能够处理200亿个未聚合的活动时间序列,数据存储成本比Thanos低50倍,专注于高基数指标的调试。
Pantheon是如何处理高基数指标的?
Pantheon采用聚合策略,去除高成本标签,同时提供服务所有者的聚合视图,以应对快速增长的基数。
Databricks如何确保监控系统的可靠性?
Databricks通过开发新的TSDB Pantheon,优化存储架构,并引入控制平面来自动化组件生命周期管理,从而提高监控系统的可靠性。
Hydra如何与Grafana集成?
Hydra直接与Grafana集成,支持PromQL查询,使工程师能够使用熟悉的界面进行高基数指标的调试。
