
Kthena + vLLM-Ascend:云原生大模型推理的编排与调度实践
💡
原文中文,约5100字,阅读约需13分钟。
📝
内容提要
本文探讨了Kthena与vLLM-Ascend在云原生大模型推理中的应用,解决了Kubernetes在分布式推理中的拓扑约束和状态感知缺失问题。Kthena通过智能调度和流量管理提升了推理效率,降低了延迟,简化了部署流程,展现了大模型服务平台的未来潜力。
🎯
关键要点
- Kthena与vLLM-Ascend在云原生大模型推理中的应用,解决了Kubernetes在分布式推理中的拓扑约束和状态感知缺失问题。
- Kthena通过智能调度和流量管理提升了推理效率,降低了延迟,简化了部署流程。
- 当前基于Kubernetes部署大模型推理面临多维度拓扑约束缺失、PD分离架构下的编排断裂和流量网关的状态盲区等挑战。
- Kthena项目通过深度集成Volcano的批处理调度能力,将分布式推理转化为具备拓扑约束的原子调度单元。
- ModelServing是Kthena架构中承载实际推理计算任务的执行单元,支持全局拓扑感知调度与Gang Scheduling。
- Kthena Router是智能流量枢纽,支持精准转发和KV Cache感知,显著提升吞吐量和降低延迟。
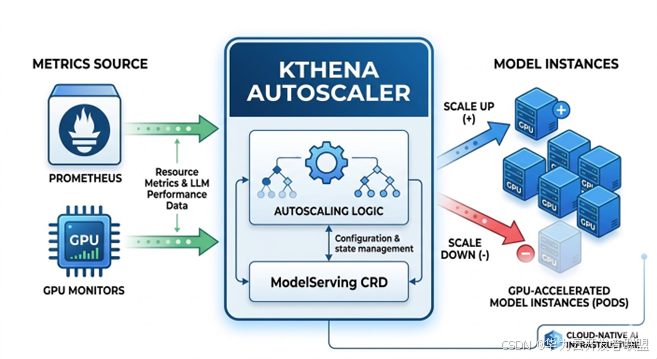
- Kthena Autoscaler实现Prefill和Decode实例的联动伸缩,确保资源高效利用。
- ModelBooster提供极简的一站式部署能力,简化了大模型推理服务的部署过程。
- Kthena与Volcano调度器的深度集成实现了多级拓扑感知与原子化调度。
- Kthena构建了一套完整的、面向生产的工程范式,未来的大模型服务平台将建立在成熟的云原生技术栈之上。
❓
延伸问答
Kthena如何解决Kubernetes在分布式推理中的问题?
Kthena通过智能调度和流量管理,解决了Kubernetes在分布式推理中的拓扑约束和状态感知缺失问题,提升了推理效率并降低了延迟。
Kthena的ModelServing是什么?
ModelServing是Kthena架构中承载实际推理计算任务的执行单元,支持全局拓扑感知调度与Gang Scheduling。
Kthena Router的主要功能是什么?
Kthena Router是智能流量枢纽,支持精准转发请求和KV Cache感知,显著提升吞吐量和降低延迟。
Kthena Autoscaler如何实现弹性伸缩?
Kthena Autoscaler通过监控Prefill和Decode实例的队列长度和请求延迟,分别进行扩缩容决策,确保资源高效利用。
Kthena与Volcano调度器的集成有什么优势?
Kthena与Volcano调度器的深度集成实现了多级拓扑感知与原子化调度,优化了分布式推理的性能。
Kthena的ModelBooster有什么特点?
ModelBooster提供极简的一站式部署能力,用户只需关注模型信息,简化了大模型推理服务的部署过程。
🏷️
标签
➡️
