
语言模型的集体意识
内容提要
语言模型的“集体意识”现象导致不同模型在开放性问题上给出相似答案。研究表明,模型间输出高度重叠,可能是由于训练数据和奖励模型的重叠。长期使用同质化工具可能限制用户思维多样性,因此在训练阶段需解决多样性问题。
关键要点
-
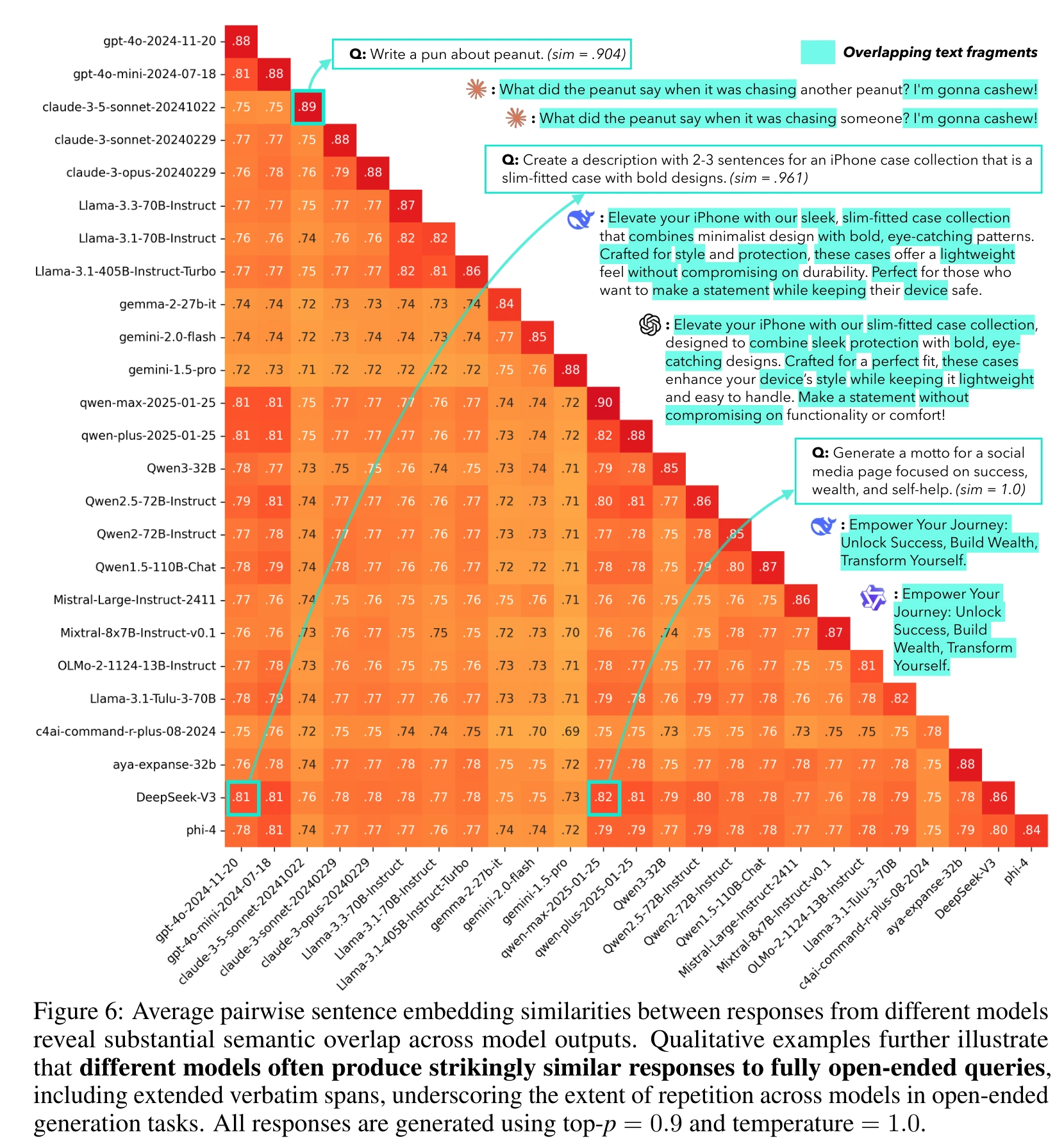
不同语言模型在开放性问题上给出相似答案,形成了“集体意识”现象。
-
研究使用Infinity-Chat数据集,包含26000个真实用户查询和31250个人工标注,评估模型输出的多样性。
-
实验结果显示,25个主流模型在相同提示下的回答高度重叠,许多模型的回答集中在少数几种表达上。
-
模型间的输出相似性高,部分模型之间的相似度达到0.82,表明不同架构的模型也会产生高度重叠的结果。
-
训练数据的重叠、奖励模型的校准问题以及合成数据的积累可能是导致同质化的原因。
-
长期使用同质化工具可能限制用户的思维多样性,尤其在需要创造性思维的领域。
-
建议在训练阶段解决多样性问题,而不是仅在解码阶段进行调整。
延伸解读
集体意识的影响
语言模型的集体意识现象使得不同模型在开放性问题上给出相似答案,这可能导致用户在创意和思维上受到限制。长期依赖这些同质化工具,可能会削弱用户的创造性思维能力,尤其在需要创新的领域。
训练数据的重叠问题
研究指出,模型输出的高度重叠可能源于训练数据的重叠和奖励模型的校准问题。这意味着在模型训练阶段需要更加关注数据的多样性,以避免未来生成内容的同质化现象。
多样性的重要性
在语言模型的应用中,尤其是在教育和决策支持等领域,输出的多样性至关重要。研究建议在训练阶段解决多样性问题,而不仅仅是在解码阶段进行调整,以确保模型能够提供更丰富的视角和创意。
延伸问答
什么是语言模型的“集体意识”现象?
语言模型的“集体意识”现象指的是不同模型在开放性问题上给出相似答案的情况,显示出高度的输出重叠。
研究如何评估语言模型输出的多样性?
研究使用Infinity-Chat数据集,包含26000个真实用户查询和31250个人工标注,评估模型输出的多样性。
导致语言模型输出同质化的原因有哪些?
导致同质化的原因包括训练数据的重叠、奖励模型的校准问题以及合成数据的积累。
长期使用同质化工具对用户思维有什么影响?
长期使用同质化工具可能限制用户的思维多样性,尤其在需要创造性思维的领域。
如何解决语言模型输出的多样性问题?
建议在训练阶段解决多样性问题,而不是仅在解码阶段进行调整。
不同架构的语言模型之间的输出相似度如何?
不同架构的模型之间的相似度高,部分模型之间的相似度达到0.82,显示出高度重叠的结果。
