
cli-trainer Skill 上线,在 AI Agent 里一键微调大模型
内容提要
星河社区推出cli-trainer,简化大模型微调流程。用户在AI IDE中输入需求后,系统自动完成环境检测、数据上传和训练提交,无需编写代码。支持多种模型和数据格式,训练后可通过API调用模型,旨在提升用户体验,减少操作步骤。
关键要点
-
星河社区推出cli-trainer,简化大模型微调流程。
-
用户在AI IDE中输入需求后,系统自动完成环境检测、数据上传和训练提交,无需编写代码。
-
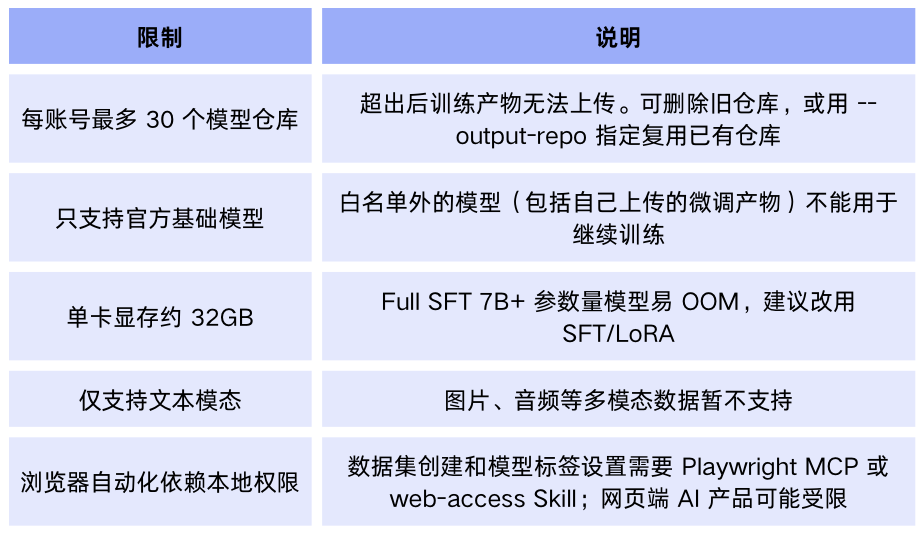
cli-trainer支持多种模型和数据格式,训练后可通过API调用模型。
-
用户需注册星河社区账号并获取Access Token,确保有训练所需的写权限。
-
支持的模型包括ERNIE系列、DeepSeek系列、Qwen2.5系列等,后续将持续扩充。
-
数据格式要求严格,文心系列需使用特定的JSONL格式,开源模型支持Alpaca和ShareGPT格式。
-
整个微调流程包括环境自检、Token验证、选模型、验数据、准备数据集、推荐超参、提交训练和监控进度。
-
训练成功后,Skill会输出训练报告并提供模型仓库地址,用户可直接调用训练好的模型。
延伸解读
简化微调流程的优势
cli-trainer的上线大大简化了大模型的微调流程,用户无需编写代码即可完成训练。这种无缝体验不仅降低了技术门槛,还能让更多非专业人士参与到AI模型的训练中,推动了AI技术的普及和应用。
数据格式的重要性
在使用cli-trainer时,数据格式的正确性至关重要。文心系列模型要求特定的JSONL格式,任何格式错误都可能导致训练失败。因此,用户在准备数据集时需仔细检查格式,以避免不必要的时间浪费和错误。
模型选择与超参数推荐
cli-trainer支持多种主流模型,用户可以根据需求选择合适的模型进行微调。同时,系统会根据数据特征自动推荐超参数,这一功能可以帮助用户更高效地进行模型训练,降低了手动调参的复杂性。
延伸问答
cli-trainer的主要功能是什么?
cli-trainer简化了大模型的微调流程,用户只需在AI IDE中输入需求,系统会自动完成环境检测、数据上传和训练提交,无需编写代码。
使用cli-trainer需要哪些准备工作?
用户需要注册星河社区账号,获取Access Token,并准备训练数据集,数据集可以来自内置公开数据集或用户自定义上传。
cli-trainer支持哪些模型?
cli-trainer目前支持ERNIE系列、DeepSeek系列、Qwen2.5系列等主流模型,后续将持续扩充支持的模型列表。
如何确保训练数据格式正确?
训练数据格式要求严格,文心系列需使用特定的JSONL格式,开源模型支持Alpaca和ShareGPT格式,格式不对会导致训练失败。
cli-trainer的微调流程是怎样的?
微调流程包括环境自检、Token验证、选模型、验数据、准备数据集、推荐超参、提交训练和监控进度等步骤。
训练成功后用户能获得什么?
训练成功后,cli-trainer会输出训练报告并提供模型仓库地址,用户可以直接调用训练好的模型。
