

Google Titans + MIRAS:终结 AI 健忘症,让模型拥有真正的长期记忆
💡
原文中文,约2600字,阅读约需7分钟。
📝
内容提要
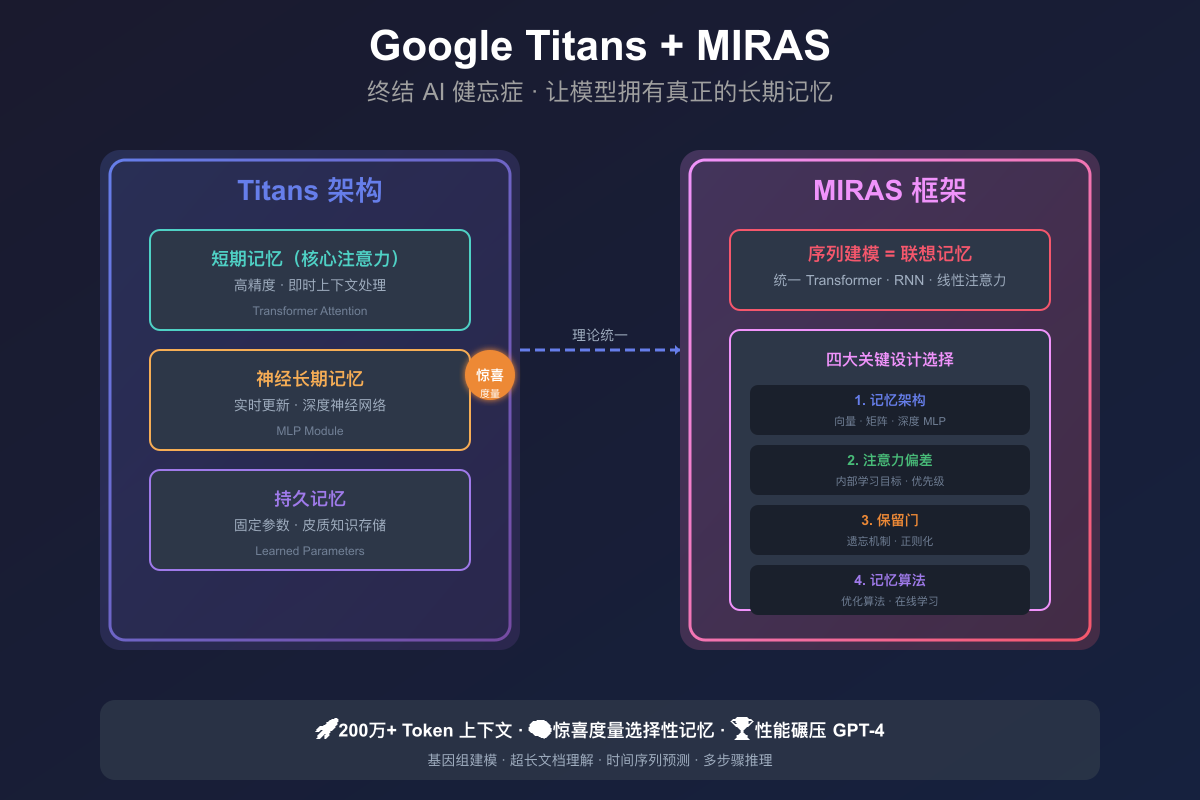
2017年,Transformer架构引入了注意力机制,但计算成本随着序列长度增加而显著上升。Google Research推出Titans和MIRAS架构,结合RNN的速度与Transformer的准确性,支持超长上下文处理。Titans模仿人脑记忆,采用短期、长期和持久记忆,通过“惊喜度量”选择性更新信息。MIRAS统一序列建模方法,拓展了设计空间,推动AI记忆系统的发展。
🎯
关键要点
- 2017年,Transformer架构引入了注意力机制,但计算成本随序列长度增加显著上升。
- Google Research推出Titans和MIRAS架构,结合RNN的速度与Transformer的准确性,支持超长上下文处理。
- Titans模仿人脑记忆,采用短期、长期和持久记忆,通过“惊喜度量”选择性更新信息。
- Titans的三层记忆架构包括短期记忆、神经长期记忆和持久记忆。
- 惊喜度量用于选择性更新重要信息,确保模型只记住新颖和重要的输入。
- Titans还引入动量和遗忘机制,确保相关信息被抓住并处理极长序列时有效管理记忆容量。
- MIRAS是序列建模的统一理论框架,将各种序列建模方法整合为一个高度复杂的联想记忆模块。
- MIRAS拆解序列模型的关键设计选择,包括记忆架构、注意力偏差、保留门和记忆算法。
- MIRAS跳出均方误差的框框,提供生成框架探索更丰富的设计空间。
- Google研究团队的实验显示,Titans和MIRAS在语言建模和常识推理任务中表现优异。
- Titans在处理极长上下文的能力上表现突出,能够有效缩放到超过200万个token的上下文窗口大小。
- Titans和MIRAS的应用范围广泛,包括基因组建模、时间序列预测、超长文档理解和多步骤推理。
- Titans和MIRAS框架标志着序列建模的重大飞跃,突破了固定大小循环状态的局限,推动AI记忆系统的发展。
➡️
