
在Kubernetes上入门PyFlink
内容提要
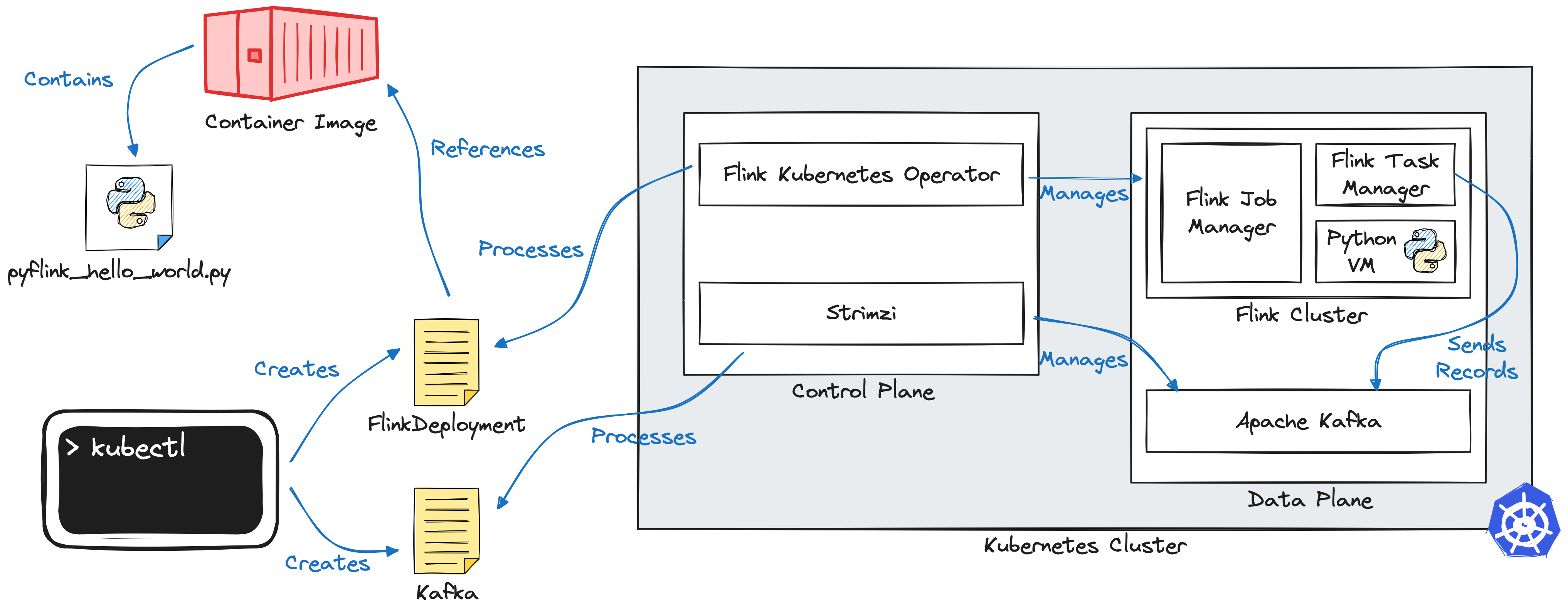
本文介绍了如何在Kubernetes上使用PyFlink,包括设置Kubernetes集群、安装Flink和Kafka操作器、创建PyFlink作业以生成随机数据并写入Kafka主题,以及通过Flink UI监控作业状态。PyFlink为Python开发者提供了强大的流处理能力,适合实时数据处理和机器学习任务。
关键要点
-
Kubernetes是运行Flink的常用平台,提供高可用性和可观察性。
-
PyFlink是Apache Flink的Python API,适合Python开发者进行实时数据处理和机器学习任务。
-
PyFlink支持批处理和流处理,提供DataStream API和Table API。
-
在Kubernetes上安装Flink和Kafka操作器的步骤包括创建集群、安装操作器和创建Kafka集群。
-
创建PyFlink作业以生成随机数据并写入Kafka主题,使用Flink的DataGen连接器和Kafka SQL连接器。
-
需要创建包含Python作业及其依赖项的容器镜像,并将其加载到Kubernetes集群中。
-
使用FlinkDeployment资源在Kubernetes上部署PyFlink作业,并通过Flink UI监控作业状态。
延伸解读
Kubernetes与Flink的结合优势
Kubernetes为Flink提供了高可用性和可观察性,使得在生产环境中运行流处理作业变得更加高效和安全。通过Kubernetes的自动扩展和资源管理功能,开发者可以更好地应对流量波动,确保作业的稳定性和性能。
PyFlink的应用场景
PyFlink适合Python开发者进行实时数据处理和机器学习任务,尤其是在需要处理实时事件数据时。结合Python丰富的第三方库,PyFlink能够有效地实现数据清洗、过滤和聚合等操作,提升数据处理效率。
注意Python版本兼容性
在使用PyFlink时,需注意Python版本的兼容性。目前,PyFlink 1.18不支持Python 3.11,建议使用Python 3.10或更早版本。这一点对于开发环境的配置至关重要,避免因版本不兼容导致的运行错误。
延伸问答
如何在Kubernetes上安装Flink和Kafka操作器?
首先创建Kubernetes集群,然后使用Helm安装Flink Kubernetes操作器和Strimzi来部署Kafka。
PyFlink适合哪些类型的任务?
PyFlink适合实时数据处理、机器学习任务以及大规模数据分析等。
如何创建一个PyFlink作业并将数据写入Kafka主题?
使用Flink的DataGen连接器生成随机数据,并通过Kafka SQL连接器将数据写入Kafka主题。
在Kubernetes上如何监控PyFlink作业的状态?
可以通过Flink UI监控作业状态,使用kubectl端口转发访问Flink Dashboard。
PyFlink与Flink的Java API有什么区别?
PyFlink是Flink的Python API,提供DataStream API和Table API,适合Python开发者使用。
在Kubernetes上部署PyFlink作业需要注意什么?
需要创建包含Python作业及其依赖项的容器镜像,并确保使用正确的Flink版本和镜像名称。
