

💡
原文中文,约9400字,阅读约需23分钟。
📝
内容提要
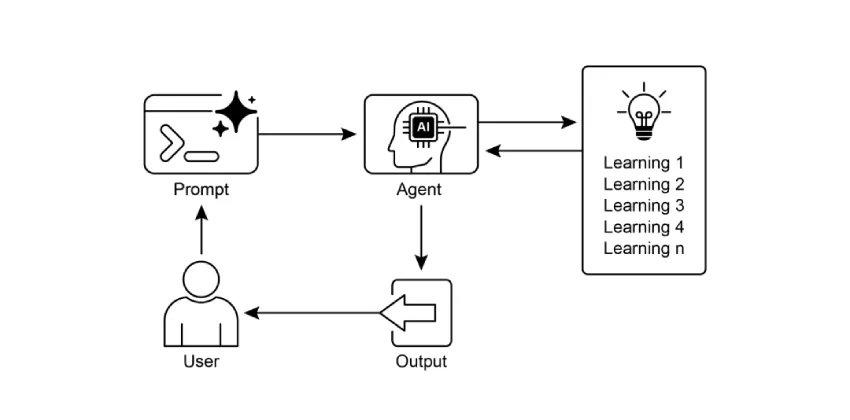
本文介绍了《智能体设计模式》第九章,讨论智能体如何通过学习与适应提升性能,涵盖强化学习、监督学习、无监督学习等方法,以及自我改进编码智能体(SICA)和Google的AlphaEvolve系统,强调智能体在动态环境中的自主学习与优化能力。
🎯
关键要点
- 智能体通过学习与适应提升性能,能够从简单遵循指令演变为更智能的系统。
- 强化学习使智能体通过奖励和惩罚学习最优行为,适用于控制机器人和玩游戏。
- 监督学习通过标记示例帮助智能体进行决策和模式识别,适合分类和趋势预测。
- 无监督学习帮助智能体在未标记数据中发现模式,适合探索数据。
- 基于大语言模型的少样本/零样本学习使智能体快速适应新任务。
- 在线学习使智能体在动态环境中持续更新知识,关键于实时反应。
- 基于记忆的学习增强智能体的上下文感知和决策能力。
- 近端策略优化(PPO)是一种强化学习算法,确保智能体策略的稳定改进。
- 直接偏好优化(DPO)简化了与人类偏好的对齐过程,避免了复杂的奖励模型。
- 自适应智能体通过经验数据驱动的迭代更新在多变环境中表现出增强性能。
- 自我改进编码智能体(SICA)展示了智能体修改自身源代码的能力,提升编码性能。
- AlphaEvolve是Google开发的AI智能体,利用LLM和演化算法发现和优化算法。
- OpenEvolve是一个演化编码智能体,利用LLM迭代优化代码,支持多种编程语言。
- 学习与适应是智能体提升工作表现和处理新情况的关键。
- 构建学习型智能体需连接机器学习工具并管理数据流动。
- AlphaEvolve推动了基础研究和实际计算应用的发展,展示了自主算法发现的可能性。
➡️
