
机器学习工程师的检查清单:可靠模型的最佳实践
💡
原文英文,约1500词,阅读约需6分钟。
📝
内容提要
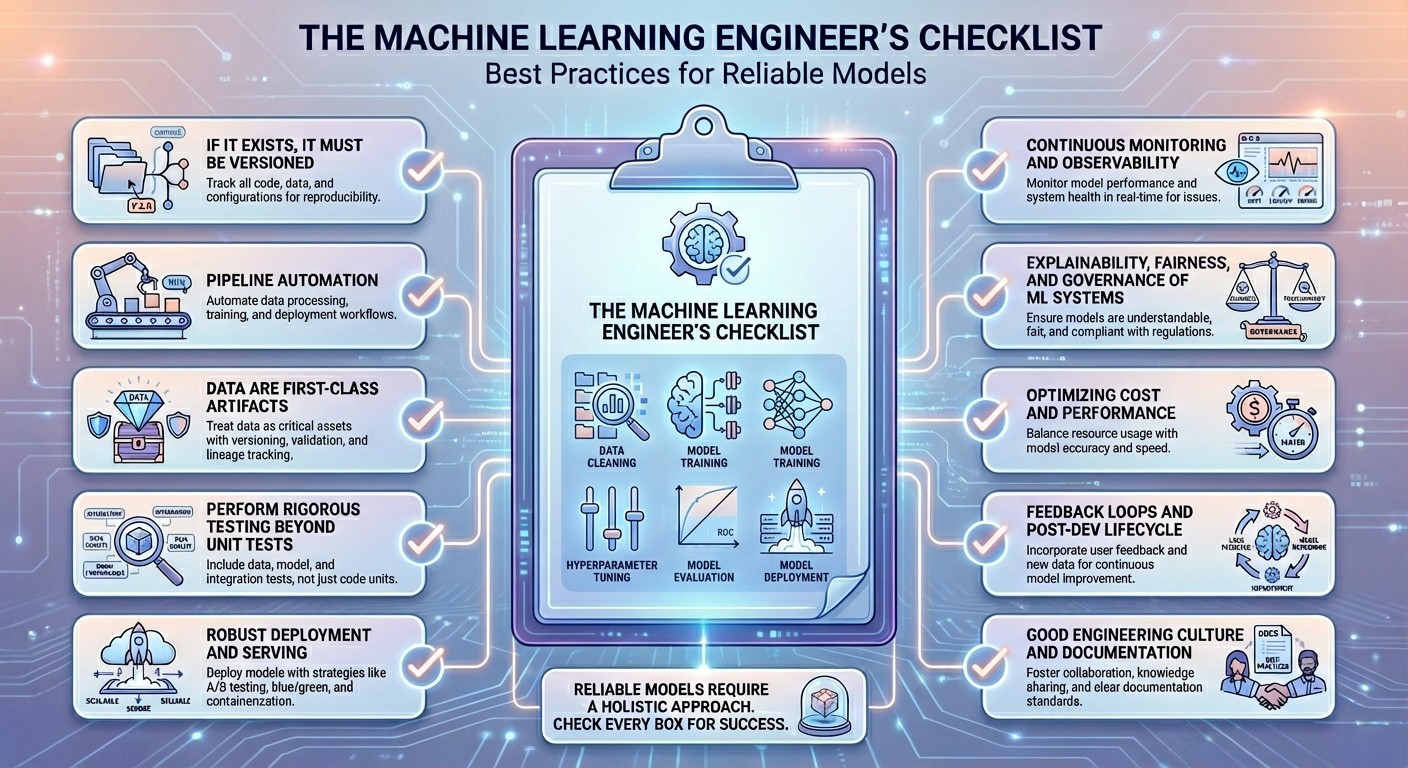
构建可靠的机器学习模型需遵循十项最佳实践:版本管理、自动化管道、数据质量、严格测试、稳健部署、持续监控、可解释性、公平性、成本优化和反馈循环。这些实践确保模型在动态环境中高效准确,避免性能下降。
🎯
关键要点
- 构建可靠的机器学习模型需遵循十项最佳实践。
- 最佳实践包括版本管理、自动化管道、数据质量、严格测试、稳健部署、持续监控、可解释性、公平性、成本优化和反馈循环。
- 版本管理确保模型生命周期中的所有数据和代码都能被追踪和复现。
- 自动化管道通过持续集成和持续交付原则,确保数据处理和模型训练的重复性。
- 数据质量至关重要,需对数据进行严格的测试和约束。
- 严格测试不仅限于单元测试,还需包括管道集成和统计一致性测试。
- 稳健的部署策略确保模型可扩展、可回滚,并能应对生产环境中的变化。
- 持续监控和可观察性帮助跟踪模型性能和业务指标的变化。
- 可解释性和公平性确保模型的透明性和合规性,避免对受保护群体的不公正对待。
- 优化成本和性能可以通过采用新技术来降低硬件消耗,同时保持模型准确性。
- 反馈循环和后开发生命周期确保模型能够适应用户偏好的变化。
- 良好的工程文化和文档化有助于减少技术债务,提高系统的可维护性。
❓
延伸问答
机器学习模型的最佳实践有哪些?
机器学习模型的最佳实践包括版本管理、自动化管道、数据质量、严格测试、稳健部署、持续监控、可解释性、公平性、成本优化和反馈循环。
为什么版本管理对机器学习模型重要?
版本管理确保模型生命周期中的所有数据和代码都能被追踪和复现,有助于快速定位问题和恢复旧版本。
如何确保机器学习模型的数据质量?
确保数据质量需要对数据进行严格的测试和约束,识别异常、重复和噪声等问题。
什么是持续监控,为什么它对机器学习模型重要?
持续监控是跟踪模型性能和业务指标变化的过程,能够及时发现数据漂移和模型衰退,确保模型的长期有效性。
机器学习模型的可解释性和公平性如何实现?
可解释性和公平性通过使用工具如SHAP和LIME,确保模型的透明性和合规性,避免对受保护群体的不公正对待。
如何优化机器学习模型的成本和性能?
可以通过采用新技术如混合精度和量化来降低硬件消耗,同时保持模型的准确性。
➡️
